 Thomas Pryce
Thomas Pryce
Git Branching Strategies for Maintainable Test Automation
Any successful project relies on three core components. People and process, along with appropriate tooling to support these two in tandem. When these...



![]() AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
AI Accelerated Quality Scalable AI accelerated test creation for improved quality and faster software delivery.
![]() Test Case Design Generate the smallest set of test cases needed to test complex systems.
Test Case Design Generate the smallest set of test cases needed to test complex systems.
![]() Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
Data Subsetting & Cloning Extract the smallest data sets needed for referential integrity and coverage.
![]() API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
API Test Automation Make complex API testing simple, using a visual approach to generate rigorous API tests.
![]() Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
Synthetic Data Generation Generate complete and compliant synthetic data on-demand for every scenario.
![]() Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
Data Allocation Automatically find and make data for every possible test, testing continuously and in parallel.
![]() Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
Requirements Modelling Model complex systems and requirements as complete flowcharts in-sprint.
![]() Data Masking Identify and mask sensitive information across databases and files.
Data Masking Identify and mask sensitive information across databases and files.
![]() Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
Legacy TDM Replacement Move to a modern test data solution with cutting-edge capabilities.
![]() Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
Events Join the Curiosity team in person or virtually at our upcoming events and conferences.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Help & Support Find a solution, request expert support and contact Curiosity.
Help & Support Find a solution, request expert support and contact Curiosity.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
Documentation Get started with the Curiosity Platform, discover our learning portal and find solutions.
![]() Integrations Explore Modeller's wide range of connections and integrations.
Integrations Explore Modeller's wide range of connections and integrations.
![]() Meet Our Team Meet our team of world leading experts in software quality and test data.
Meet Our Team Meet our team of world leading experts in software quality and test data.
![]() Our History Explore Curiosity's long history of creating market-defining solutions and success.
Our History Explore Curiosity's long history of creating market-defining solutions and success.
![]() Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
Our Mission Discover how we aim to revolutionize the quality and speed of software delivery.
![]() Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
Our Partners Learn about our partners and how we can help you solve your software delivery challenges.
![]() Careers Join our growing team of industry veterans, experts, innovators and specialists.
Careers Join our growing team of industry veterans, experts, innovators and specialists.
![]() Press Releases Read the latest Curiosity news and company updates.
Press Releases Read the latest Curiosity news and company updates.
![]() Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
Success Stories Learn how our customers found success with Curiosity's Modeller and Enterprise Test Data.
![]() Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
Blog Discover software quality trends and thought leadership brought to you by the Curiosity team.
![]() Contact Us Get in touch with a Curiosity expert or leave us a message.
Contact Us Get in touch with a Curiosity expert or leave us a message.

Data is the lifeblood of any modern organisation, the majority of which today use Business Intelligence tooling to inform critical decisions.
Insights provided by BI dashboards depend on information flowing smoothly across the systems in use at an organisation, all converted into analysable formats. However, the transforms that move and covert this mass of data are rarely tested sufficiently, exposing information to inaccuracies.
Organisations in turn risk basing decisions on out-of-date and inaccurate data. At best, that means missed opportunities and procedural inefficiency; at worst, it spells catastrophic losses from fatal errors. This article explores common bottlenecks in Extract-Transform-Load (ETL) testing, and how automated ETL testing can instead be both rigorous and reactive to change.
Extract-Transform-Load denotes the movement of data between systems, usually preparing it for use by Business Intelligence dashboards and tools. Today, this typically requires preparing data for use by messages, flat files, and calls to APIs.
There are two broad challenges for developers and testers responsible for creating and validating data transforms.
First, the size and complexity of the data, reflected in the complexity of the transforms. Already in 2015, BigInsights found that nearly one in five organisations stored more than 1 petabyte of data. That figure is only likely to grow, with the amount of data held globally forecast to swell to 163 zettabytes by 2025, ten times the amount in 2017, with the IDC predicting that organisations will create 60% of that data.
The data is not just huge, but complex. It is stored across numerous files, pre-packaged applications, mainframe systems, and relational databases. That equates to masses of slightly differing data, in different formats, all needing to be converted and moved across systems quickly.
A second challenge is the rate at which business requirements change, generating the need for new masses of data, and for ETL rules to be updated rapidly. Developers and testers might spend whole iterations mastering and testing a transform, only to find that it has grown out-of-date by the time it has been executed.
ETL testing practices have not kept pace with data growth and change. The following section considers how all-too-traditional approaches to ETL testing hinder both the speed and quality required for true Business Intelligence.
ETL testing in its broadest definition means inputting test data into applications that transform data, and comparing the resultant data with the expected results. Such testing is regularly riddled with slow and manual processes that are no match for the complexity of data transforms. These include:
The complexity of data translates directly into the complexity of ETL testing, with a huge variety of possible scenarios that could be tested. The greater the number of values and variables in the data, the greater the number of scenarios. This grows exponentially as the data estate grows.
Rigorous ETL testing requires that test cases and data not only reflect the latest transformation rules, but has enough variety to exercise the logic contained across the myriad of scenarios. And that’s typically hundreds of thousands, if not millions – more than any one person could think up in their heads.
Nonetheless, test teams frequently formulate test cases and test plans manually, unsystematically writing up tests. These test cases are typically highly repetitive and pick off the most obvious scenarios first, resulting in slow test case design which only exercises a fraction of a transform’s logic. Negative testing is basically non-existent and the bulk of possible scenarios are left untested, exposing data transforms to inaccuracies.
Expected results are also hard to define for ETL testing, and this is usually done inaccurately or incompletely. The problem is then that test teams simply have no way of knowing if a tests have passed or not, or if data transformations are performing correctly.
Then there’s the data that’s inputted into the system under test. This is often production data that has been painstakingly copied into a test environment, rendering it out-of-date by the time it’s ready for use.
What’s worse, production data is almost always low variety, capable of testing only a fraction of the possible scenarios. It by definition reflects a previous version of the transformation logic, while the bulk of data inputted during production is made up of “happy”, business as usual scenarios.
The outliers and unexpected scenarios that are most likely to cause critical errors must be created by hand, along with any new data scenarios. This creates a further slow and manual process.
In addition to compromising speed and quality, testing with production data risks non-compliance with ever-more stringent and potentially costly data protection regulations. Test environments are necessarily less secure than production, while organisations who use production data in testing rely on testers following complex requirements, such as those set out in the EU Data Protection Regulation.
Increasingly stringent regulations set out when certain types of personal data can be used, by whom, and with what permissions. Get it wrong and it might cost 4% of annual revenue in fines.
Masking data for testing is an option, but introduces another slow and complex process where the complex interrelations within production data must be retained. Get that wrong and testing is using inaccurate data, again exposing ETL rules to defects.
The logistics of executing the tests creates further bottlenecks. Test data is refreshed manually, inputting it through the system under test. This generates vast quantities of resultant data, which must then be compared to the expected results to validate the transform.
It’s not uncommon to see testers comparing data by eye, row-by-row in a spreadsheet. This is not only slow, but haphazard, exposing business-critical data transforms to the human errors that creep into any highly repetitive task.
If a change occurs, either the whole testing cycle must begin anew, or the masses of existing test cases must be checked for validity, and the test data refreshed.
This repeats much of the slow and manual effort of the initial testing, where a lack of traceability between the business and testing logic prevents any real degree of automation in test maintenance. Testing quickly falls behind, and can provide no guarantee that Business Intelligence is being underpinned by accurately transformed data.
In short, traditional testing methods are incapable of delivering the rigour required for reliable Business Intelligence, at the speed with which ETL rules change. Testing is instead slow and suboptimal at every phase:
✘ Slow and manual test creation only tests a fraction of possible scenarios, while expected results are unknown or poorly designed.
✘ Low-variety test data prevents rigour, slowly copying production data that risks legislative non-compliance and does not contain the data needed for complete testing.
✘ Execution is slow and erroneous, manually inputting large quantities of complex data before comparing actual and expected results by eye.
✘ Test maintenance cannot keep up with change, refreshing and re-editing data by hand and checking the thousands of existing test cases each time business requirements change.
Model-Based Testing offers an accurate way to automate many of the manual processes that slow ETL testing down. It enables a structured approach to generating test cases and data that are optimised to test the most important data scenarios within a testing cycle.
The test cases and data are both linked to the model, which is aligned closely with business logic. As ETL rules evolve, the model can then be quickly updated, automatically re-generating and re-executing a rigorous set of tests: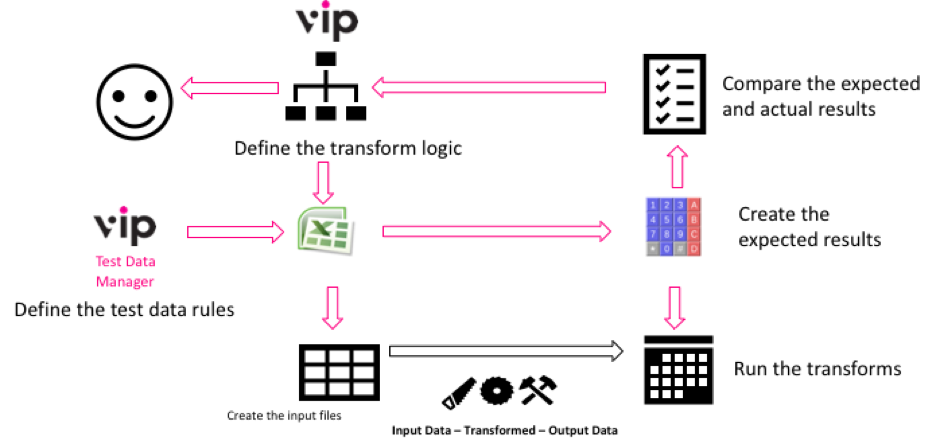
Models drive End-to-End automation of ETL testing, from defining the test cases and
data, to generating the input files and calculating the test results.
VIP, Curiosity’s complete testing framework, offers such a Model-Based approach. Complex data transformations are modelled accurately as easy-to-use Business Process Models, before applying advanced coverage techniques to generate the most rigorous set of test cases based on time and risk.
Powerful but simple test data generation functions create data with which to execute every generated test, and the data is furthermore inputted automatically. Each stage of ETL testing is automated and optimised in this approach, enhancing the speed and rigour throughout:
Intuitive, easy-to-use models drive otherwise complex ETL testing with VIP. A drag-and-drop approach quickly builds the visual models from business requirements, with a range of connectors to accelerate the modelling process. What’s more, when a model has been created once, it can be re-used rapidly as a subprocess, dragging-and-dropping it to a master flow.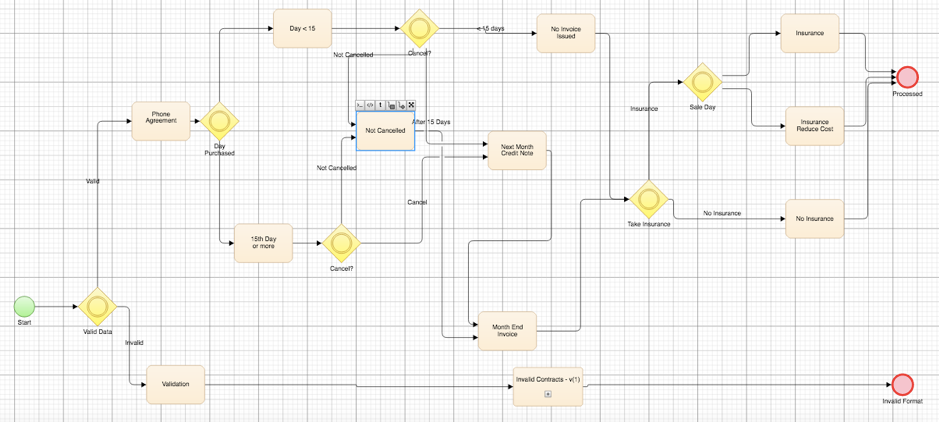
A VIP Test Modeller Flowchart for processing phone contract invoices based on the validity
of the contract, the date, and any insurance claims. A subprocess is used to handle the
negative testing entailed by an invalid contract.
The flowchart-style models in VIP consolidate logic otherwise stored in disparate requirements or linear test cases. This makes missing logic far easier to spot. For instance, a “condition” (decision) block might obviously be missing a branch, while automated and mathematical checks begin to identify logic left out of the requirements.
Visual modelling helps weave negative scenarios into testing, working towards complete models to drive testing, while also remediating some of the defects that stem from incomplete business requirements.
The model serves as a directional graph, where the paths from its start and end points are equivalent to test cases. The mathematical precision of the model means that automated algorithms can be applied to identify all the test cases, just as a GPS can calculate possible routes through a street map.
Automated test generation is not only faster than manually and repetitively writing test cases, it is almost always more rigorous too. The VIP Test Modeller provides granular coverage techniques with which to generate test cases, automatically creating a set of tests that cover a model from “low” to “exhaustive”.
Exhaustive test generation for new or critical logic creates tests for every kind of data scenario, including the unexpected results and outliers most likely to cause transformation defects. Alternatively, tests might be optimised for time and risk, flagging critical functionality for high or exhaustive testing, while exercising the logic in the remaining model as much as possible based on available resources.
The result is optimised testing, performed quickly and with confidence that transformations are performing as they should, and for the right reason.
VIP further finds and creates test data to execute every test case as they are generated.
A comprehensive set of test data generation functions are available within the Modeller and as an Excel Add-In, and are used in the same way as standard Excel functions. The combinable, easy-to-use functions define the minutiae of test data for every possible scenario, including the unexpected results and outliers needed for rigorous testing.
Functions are resolved dynamically as tests are created by VIP, while data can be called and manipulated “just in time” from databases and files using Excel and VIP connectors.
The result is a rigorous set of test cases, created with complete data that reflects the very latest transformation logic. In contrast to slowly copying out-of-date production data, this approach quickly generates realistic data with enough variety to exercise the logic contained across all possible scenarios, for accurate ETL testing that is rigorous and efficient.
Having automatically generated test cases and data, VIP further replaces slow and manual data inputs with automated test execution. It assembles input files from the complete test cases and data, before providing high-performance process automation to input the data across the system under test.
A high-speed VIP workflow will run non-invasively in the background to execute the tests using existing testing technologies. What’s more, VIP will capture the masses of resultant data automatically, and will perform one of the most resource-intensive parts of manual ETL testing: comparing the actual and expected results.
Test results are furthermore inputted into existing testing and ALM platforms as part of the same automated process. This achieves end-to-end automation, from rigorous test case design, to high-performance execution and accurate reporting.
Test maintenance is also automated by the VIP Test Modeller, enabling rigorous ETL testing that occurs within the same iteration as any changes made to transformation rules.
Test cases and test data are both traceable back to the central model, which provides a single point of reference for updating the test suite. Simply updating the model will edit all the existing test cases, which are then regenerated along with the test data needed to execute them.
A Model-Based approach to ETL testing can introduce a greater degree of automation and rigorous, driving up the reliability of insights provided by Business Intelligence tools. Using VIP, ETL testing is automated, optimised, and accelerated at every phase:
✓ Test case design is comprehensive, using powerful coverage algorithms to generate a rigorous set of test cases from easy-to-use process models.
✓ Every scenario is covered by test data, using powerful but simple generation functions that dynamically resolve as tests are created.
✓ Test execution is high-performance, with VIP workflows that work in the background to input data and calculate test results.
✓ Testing keeps up with the rate of change, by simply updating a central model to reflect changes made to transformation rules in test cases and data.
To see this automated approach to rigorous ETL testing in practice, please watch our end-to-end demo:
If you have any questions or would like to set up a free trial and demo, please get in touch.

[image: Pixabay]

Any successful project relies on three core components. People and process, along with appropriate tooling to support these two in tandem. When these...

Banks globally rely on Oracle FLEXCUBE to provide their agile banking infrastructure, and more today are migrating to FLEXCUBE to retain a...

Continuous Integration (CI) and Continuous Delivery or Continuous Deployment (CD) pipelines have been largely adopted across the software development...

Each year, organisations and consumers globally depend on Oracle FLEXCUBE to process an estimated 26 Billion banking transactions [1]. For...

Despite increasing investment in test automation, many organisations today are yet to overcome the barrier to successful automated testing. In fact,...

This is Part 1/3 of “Introducing “Functional Performance Testing”, a series of articles considering how to test automatically across multi-tier...

This is Part 3/3 of “Introducing “Functional Performance Testing”, a series of articles considering how to test automatically across multi-tier...

Throughout the development process, software applications undergo a variety of changes, from new functionality and code optimisation to the removal...

Test teams today are striving to automate more in order to test ever-more complex systems within ever-shorter iterations. However, the rate of test...