



Today, any test data solution must be capable of fulfilling data requests of a greater volume, variety, and complexity, faster than ever before. This often-pressing need is not always fully appreciated by organisations, but is seen in negative consequences that include:
- Growing testing bottlenecks.
- An increase in erroneous test failures.
- Lost productivity across the SDLC.
- Mounting infrastructure costs.
- Ongoing compliance risks.
Numerous factors have led to this increase in pressure on already-strained test data services. This article considers related trends that have added to the frequency, volume, and complexity of requests for test data made today. These new and ongoing trends fall into five broad buckets, which must be considered when designing a robust test data solution:
- The complexity of interrelated data types.
- The pace and magnitude of changes in systems, environments, and production data.
- A greater degree of parallelisation across testing and development.
- The adoption of automation in testing and the changing nature of a “data requester”.
- Evolving compliance requirements.
The potential risk posed to software delivery speed and quality by these related trends calls for a move beyond outdated test data “provisioning” practices. It calls for an automated solution, capable of fulfilling new and evolving test data requests on-the-fly. This ability for parallel teams, tests and frameworks to self-provision data on demand is a key difference between Test Data Management (TDM) and Enterprise Test Data (ETD).
1. The complexity of interrelated data sources
A test data solution today cannot populate isolated data into a limited number of databases and file types. Testing and development instead requires rich and compliant data that consistently spans numerous legacy and cutting-edge technologies.
This integrated, interrelated data is necessary for integration and end-to-end testing, but adds substantially to the complexity of data needed in testing. A range of trends in Enterprise Software and IT have led to a proliferation in the data types used at organizations today. They include:
- The ongoing move from legacy to web- and cloud-based infrastructure.
- The emergence of Big Data and AI, along with the associated technologies for data storage, analytics, and processing. This often includes open source technologies like Apache Hadoop, Spark, Kafka, and Solr.
- The adoption of new database and file types. This includes graph databases like Neo4j, as well as the adoption of databases that have emerged in the 21st Century, such as MariaDB and Firebird.
- The crucial importance of APIs and message layers today. This has led to the need to create message data like XML files, as well as industry-specific formats and standards.
- The continuous evolution of Business Intelligence technology.
- The adoption of microservices.
While organizations are continuously adopting new technologies, these emergent data types do not replace existing legacy components wholesale. Migrations take time and few organisations have the luxury of replacing entire elements of their technology stack in one go.
It is therefore common to find a mix of new and legacy data types used across different parts of an Enterprise. For example, different parts of an organization might use modern, cloud-based technologies, while others use proprietary data types stored on Mainframe and midrange systems. The old and the new must typically interact and integrate, using the range of interfaces available today: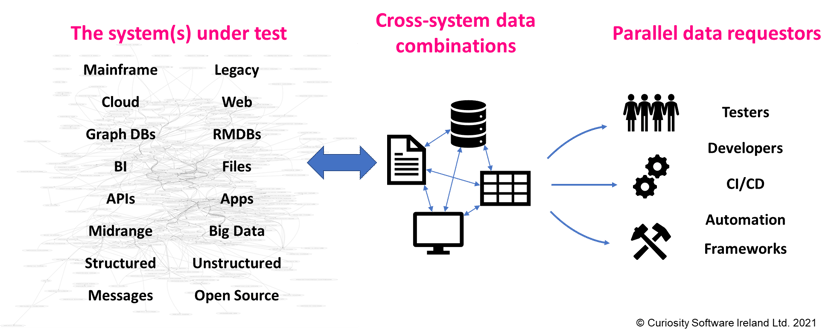
Testing today requires integrated combinations of data that span a diverse range of technologies.
Any test data solution must usually therefore be capable of analyzing, manipulating, and creating integrated data for a more diverse range of technologies than ever. It should be equipped with extensive and extensible connectors, and must be capable of creating integrated data across different files, databases and applications in tandem.
The plurality and complexity of data types adds to the complexity of data requests made today, as testers and developers require integrated data that links seamlessly across a wide range of technologies. At the same time, the pace and evolution of data requests is growing, increasing the speed and diversity of data requests being made today.
2. Iterative delivery, agile software development, and CI/CD
Several trends from across software delivery have increased the rate of change in data needed for testing and development, adding pressure to test data provisioning. These trends have boosted the pace and magnitude of changes in systems, environments, and production behavior, demanding new and increasingly diverse test data. They include:
- The rise of iterative delivery, in which new releases and updates arrive in days or weeks, rather than months or years.
- The adoption of agile software development practices, with their emphasis on incremental changes and parallelization.
- Increased automation and new technologies in DevOps pipelines and CI/CD, enabling rapid changes to be developed continuously and integrated into existing systems.
Each rapid change renders existing data out-of-date and often obsolete. Existing data might not match the latest system logic and data structures. Meanwhile, gaps arise in coverage as historical data lacks the data combinations needed for testing new or updated logic. While the gaps in test coverage risk bugs, inconsistent or invalid combinations risk erroneous test failures and bottlenecks.
The three trends listed above have also increased the pace and volume of data requests, as each emphasize parallel ways of working. A test data solution can no longer provision relatively static sets of data to a limited number of teams. Up-to-date data must instead be made available to numerous cross-functional teams and automated frameworks.
Any test data solution today must usually be capable of making up-to-date and complete data available at the pace with which parallelized development teams evolve complex systems. Testing and development requires constantly changing data sets, available in parallel and on-the-fly. The on demand data must furthermore be fully versioned, capable of testing different combinations of versioned system component.
3. Containerisation, source control, and readily reusable code
Not only is the pace of system change growing; the magnitude of changes being made to complex systems today can be greater than ever. This presents a challenge to slow and overly manual data provisioning, as a substantial chunk of data might need updating or replacing based on rapid system changes.
A range of practices in development have increased the rate and scale of system change. The adoption of containerization, source control, and easily reusable code libraries allow parallelized developers to rip and replace code at lightning speed. They can easily deploy new tools and technologies, developing systems that are now intricately woven webs of fast-shifting components.
A test data solution today must be capable of providing consistent test data “journeys” based on the sizeable impact of these changes across interrelated system components. Data allocation must occur at the pace with which developers chop-and-change reusable and containerised components.
This will typically require a tighter coupling of system requirements, tests, and code, rapidly identifying what data is needed based on changes from across the entire SDLC. Otherwise, testing bottlenecks and errors will arise as testers and developers lack the up-to-date data they need to deliver rigorously tested software in short iterations.
4. Automation in testing
Test automation is another key development that has increased the continuous need for up-to-date data in testing and development.
Test execution automation and CI/CD have substantially increased the speed and volume of data requests. Data hungry frameworks tear through data faster than manual testers ever could, often running large test suites overnights and on weekends. The same tests are furthermore typically parallelized, adding to the demand for data.
In addition to increasing the speed with which data is required, automated tests further exacerbate challenges associated with inaccurate data provisioning. Scripted tests are less forgiving than manual testers, who can adjust their testing if data is incomplete, invalid, or used up. An automated test will simply fail if data is invalid, out-of-date, or missing. This adds to bottlenecks in testing and development, as bugs mis-identified during automated testing require investigation.
Test automation has changed the nature of a test data requester today. Effective test data solutions today should typically provide on demand access to manual testers and developers, as well as technologies like test automation frameworks and CI/CD pipelines. Both humans and programs should be capable of parameterizing and triggering test data jobs on-the-fly. This is another key difference between traditional Test Data Management and Enterprise Test Data.
5. Evolving data privacy requirements
The last set of developments that have complicated and called for a revision of test data “best practices” lie in data privacy requirements and regulations.
Curiosity have written extensively about the potential repercussions of the EU General Data Protection Regulation (GDPR) for testing and development. The EU GDPR has already led organisations to forbid the use of raw production data in testing, as they strive to comply with stricter rules governing data processing. These rules often limit how and when data can be used, by who, and for how long.
Legislation like the EU GDPR also presents particular logistical challenges for traditional test data best practices. Organisations today might need to locate, copy and delete every copy of a person’s data “without delay”. That typically requires greater control and oversight into how data is being used in testing and development, as well as rapid and reliable mechanisms for locating data across non-production environments. Often, a safer and simpler approach is to avoid copying sensitive information to less-secure, less-controlled testing and development environments.
While the EU GDPR was a watershed moment for data privacy in many aspects, it was not an isolated development. It reflects a broader direction of travel globally, in which numerous countries have adopted legislation that are in ways comparable to the EU GDPR.[i] These global legislative moves might have similar repercussions for the use of data in testing. They include legislation like the UK GDPR, Canada’s CCPA, India’s PDPB, and Brazil’s LGPD.
Evolving data privacy requirements can increase the complexity of managing test data, as well as the degree of overall controlled needed over data in non-production environments. Organisations who are already struggling to get data of sufficient variety and volume to testers and developers might not welcome the thought of not being able to provision data, let alone having to remove and limit the use of existing test data. Yet, the risks of non-compliance can be severe.
Enterprise Test Data and the promise of AI
Many new and ongoing trends mean that today data of a greater volume and variety is needed faster than ever in testing and development. This article has identified just some of these factors, which include:
- The emergence of new and interrelated data sources and targets, requiring consistent and intricately related data.
- The speed and magnitude of changes in systems, environments, and production, requiring new and continuously evolving data for testing and development.
- A greater degree of parallelisation across testing and development, requiring rich and often voluminous data on demand and in parallel.
- The adoption of automation in testing, changing the nature of a “data requester” and requiring accurate data of greater volumes and variety.
- Evolving data privacy regulations, calling for greater governance of how and when sensitive data is used in non-production environments.
These trends are increasing the pressure on already-strained test data “provisioning” services, adding to delays and undermining quality in testing and development. This calls for a revision of test data “best practices”. One approach empowers parallel teams and automation frameworks to self-provision rich, complete, and compliant data on-the-fly.
Footnotes:
[i] For a good overview, see Dan Simmons (12/01/2021), 13 Countries with GDPR-like Data Privacy Laws. Retrieved from https://insights.comforte.com/13-countries-with-gdpr-like-data-privacy-laws on 23/11/2021.


