Every year, enterprises invest substantial resources in software projects, directing a large share of that budget to initiatives that promise to enhance delivery productivity. Yet, despite these investments, organisations often struggle to meet speed and quality expectations. I frequently hear from industry leaders that, even with improved tooling and methodologies, these same challenges still persist across delivery.
Why do these gaps exist?
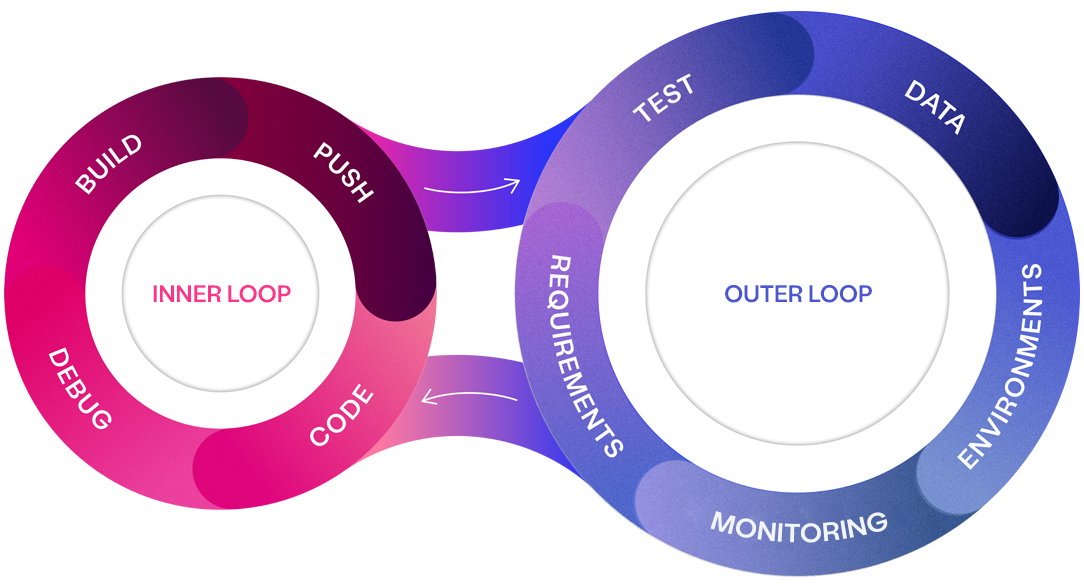
To understand the root of this issue, we must break down the software delivery process into two key areas: the inner loop and the outer loop. The inner loop encompasses coding, building, and integration—the core activities of software development. Surrounding these tasks is the outer loop, which involves requirements definition, test data creation, testing, and ongoing maintenance.
While significant attention has been paid to optimising the inner loop, inefficiencies in the outer loop can severely undermine the productivity of even the best development teams. When requirements are unclear, or test data is not readily available, it creates bottlenecks and confusion, causing rework and delays throughout the entire delivery pipeline. The net effect is quality and productivity suffer.

An efficient and effective outer loop is critical for overall software delivery productivity and quality.
Surviving Software Delivery in 2025
Join James Walker and Rich Jordan for an insightful webinar exploring the most common hurdles faced by software delivery teams and practical strategies to overcome them.


The model-driven approach
To address these outer loop challenges, a model-driven approach leverages visual and structured representations to guide every phase of software delivery. Visual models help reduce ambiguity, improve collaboration, and ensure a shared understanding among stakeholders. This ensures that high-quality inputs—such as clearly defined requirements and ready-to-use test data—are available before any coding begins. With well-aligned inner and outer loops, organisations can achieve faster, higher-quality outputs from the delivery process.

Shifting quality left means focusing efforts early on creating high quality assets which promote quality and productivity across software delivery.
The evolving landscape of software delivery
In a recent Curiosity-hosted webinar, we posed the question: “Is software getting better or worse?” One key takeaway was the dramatic shift in how software is developed and delivered. Over the years, teams have transitioned from rigid, sequential processes like Waterfall to more flexible, iterative methodologies like Agile. This shift has enabled businesses to release software more frequently, with daily releases now becoming the norm as organisations strive to deliver value faster. Software has become a core driver for nearly every business, whether they are traditionally tech-centric or not. This increased reliance on software has, in turn, heightened competition, forcing companies to innovate at a relentless pace just to stay ahead.
With this evolving landscape, new challenges are arising across delivery:
- Quality across the software development lifecycle (SDLC)
Requirements today are often incomplete, ambiguous, or overly complex, making implementation challenging and lowering downstream quality. - Dependence on high-coverage data
Organisations thrive on accurate, structured data. Without comprehensive coverage of scenarios developers and testers to not have the data they need to perform their tasks quickly and effectively. - Increased importance of testing
AI-generated code, while accelerating development, is prone to subtle errors. Testing is now more critical than ever to ensure reliability and robustness. - Fostering cross-team collaboration
Distributed teams working in silos often face knowledge gaps and misalignment. Shared visual models can serve as a universal blueprint, enhancing communication and collaboration. - Boosting productivity amid complexity
Teams are being pushed to deliver more with fewer resources. Structured visual models help streamline workflows, enabling teams to keep up with the accelerated pace of modern software development. - Addressing technical debt
Rapid iterations often leave behind technical debt, which needs to be strategically managed to sustain quality.
AI as a transformative technology
The final addition is AI which will undoubtably reshape how software is developed. Current AI efforts are being targeted towards developing coding agents that develop code without the need of developers. While the initial results are impressive, for AI to be effective it must be fed high-quality inputs, in the form of well-defined robust requirements. The principle of "garbage in, garbage out", directly translates to “quality in, quality out” when applying AI in a software delivery context.
Translating textual statements into code is already a largely solved problem with large language models. While issues such as hallucinations and accuracy exist, they are expected to improve over time as the number of parameters grow, and models are find-tuned to specific coding tasks. With this in mind, we believe the role of developers will evolve, with a focus away from directly writing lines of code onto higher-level problem-solving, with agents undertaking the majority of coding. This evolution requires bridging a gap in communication with AI, in a clear and structured language, removing ambiguity about what needs to be created and the underlying business rules / logic that needs to be embedded – a gap which modelling is in pole position to resolve.
While textual requirements can work, they present numerous challenges even from a human software delivery perspective. Visual model offers clarity, starting at a high level and going as deep as needed into the implementation details. It provides a mechanism for collaboration and visualisation that is not feasible with text alone. Visual models offer clear, unambiguous representations of requirements, ensuring AI has a solid foundation to work from. Iterative refinement of these visual models further improves the quality and reliability of AI-generated solutions.
Moreover, as AI-generated code often contain errors or unexpected behaviours from hallucinations, rigorous testing becomes mission critical to have trust and confidence in the AI generated solutions.
Modelling across software delivery
Modelling is a powerful approach to overcoming the inefficiencies commonly found in software delivery, particularly within the outer loop. By creating clear and precise specifications from the outset, organisations can ensure that all essential components—such as requirements, test cases, and data—are well-defined and aligned before development begins. This early clarity enables teams to streamline development activities, reduces rework, and accelerates delivery by providing a comprehensive blueprint that guides development, testing, and final validation.
The following sections explain how modelling supports various stages of the software development lifecycle, including requirements gathering, design, quality assurance, testing, and ongoing management of technical debt
1. Model-driven requirements
High-quality requirements are the backbone of effective software delivery. Traditionally, requirements are often captured in text-based formats, such as user stories or lengthy documents, which are prone to ambiguity and misinterpretation. Modelling overcomes these limitations by transforming textual requirements into visual, structured representations that are easy to understand and communicate.
This visual approach not only provides clarity but also fosters collaboration among stakeholders. By involving business analysts, developers, testers, and other teams early in the modelling process, organisations can ensure that requirements are fully captured, validated, and agreed upon before any development work begins. This collaborative effort helps bridge communication gaps, reduces misunderstandings, and minimises costly rework later in the cycle.

Visual models also help break down complex requirements into smaller, manageable components, starting from high-level objectives and progressively refining them into detailed technical specifications. This structured decomposition provides a clear view of what needs to be built, making it easier to trace requirements through to implementation. In this way, visual models serve as a single source of truth that all teams can reference throughout the development lifecycle, ensuring alignment and reducing the risk of misinterpretation.
2. Aligned and efficient development
One of the biggest challenges in software development is ensuring that what gets built matches what was originally envisioned. Misinterpretations, vague requirements, and a lack of shared understanding often lead to developers building the wrong solution, causing rework, delays, and wasted effort. Visual models address these issues by turning ambiguous, text-based requirements into clear, visual blueprints that define what needs to be built and how each part of the system should behave. With visual models, every stakeholder—whether a business analyst, developer, or tester—can see the same representation of the system, which eliminates guesswork and aligns expectations. This shared understanding reduces ambiguity and ensures that all contributors are on the same page before a single line of code is written.

During development, visual models serve as a reference point that developers can continuously consult to ensure their work is on track. Instead of relying on incomplete user stories or lengthy documentation that’s open to interpretation, developers can use the visual models to validate that their implementation aligns with the overall design intent. This structured approach minimises fragmentation and integration issues, especially in complex projects where multiple teams are contributing simultaneously. By using visual models to guide implementation, teams can reduce defects, streamline collaboration, and ultimately deliver software that faithfully meets the original requirements, ensuring that the right solution is built correctly from the start.
3. Model-driven quality
Model-driven quality assurance is essential for achieving both comprehensive test coverage and high software quality. By leveraging visual models that represent system logic, workflows, and data flows, QA teams can derive precise test plans that ensure coverage across all critical components and business scenarios. This approach goes beyond traditional test design by validating every pathway and interaction within the system, ensuring that no functionality is left untested and that potential edge cases are addressed.
Visual models serve as a structured blueprint that link requirements to implementation, providing QA teams with a clear view of the system's behaviour and helping them identify gaps or ambiguous areas early on. This clarity enhances the accuracy of test coverage, reducing the risk of missing critical defects. With visual models, teams can also visualise complex scenarios, simulate different outcomes, and prioritise testing based on the impact and risk of each component, making coverage not just thorough, but also highly strategic.

Additionally, by focusing on early detection through model-driven analysis, QA teams can pinpoint potential failure points and quality issues long before testing begins. This proactive approach reduces the cost of resolving defects, accelerates testing cycles, and ultimately results in more reliable, higher-quality software. Comprehensive test coverage, combined with early validation of design and requirements, forms the backbone of effective quality assurance, ensuring that both functional and non-functional aspects of the system meet business expectations.
4. High coverage test data
Test data is a critical but often overlooked aspect of software quality. Without the right data, even the most well-designed tests will not provide meaningful insights. Models address this challenge by specifying data requirements in detail, enabling teams to generate realistic and comprehensive test data sets before testing begins.

With a clear understanding of the data needed for different test scenarios, teams can automate the generation of synthetic test data that accurately reflects each scenario. This capability ensures that test data is available when needed and that it covers a wide range of scenarios, from edge cases to standard workflows (data coverage).
5. Model-driven test automation
Models can also be leveraged to drive test automation, making the entire testing process more efficient and reliable. By generating test scripts directly from the models, organisations can ensure that tests are consistent, repeatable, and aligned with the requirements. This model-based approach to testing improves test coverage and enables faster iterations, allowing teams to detect and resolve issues earlier in the development lifecycle.

Continuous testing, supported by models, ensures that every change to the system is validated against the original specifications. As the models are updated to reflect new features or changes in the system, test cases are automatically adjusted, maintaining alignment and ensuring that the software remains in a validated state throughout the development cycle.
6. Managing technical debt with models
Technical debt is an inevitable part of software development, but models provide a systematic way to manage and mitigate its impact. By offering a structured view of the system architecture and requirements, models make it easier to identify areas where technical debt has accumulated, such as outdated components, workarounds, or incomplete implementations.
Visual models can highlight areas that require refactoring, helping teams prioritise technical debt reduction based on factors such as risk, complexity, and business impact. This visibility enables more strategic planning, allowing teams to allocate resources effectively and address technical debt in a way that minimises disruption.

Furthermore, because models serve as living documentation, they help prevent the accumulation of new technical debt by ensuring that all changes are well-documented and aligned with the overall system design. This approach reduces the likelihood of introducing unintended complexities and makes it easier to maintain software quality over time.
The future with AI
Incorporating AI into model-driven quality assurance opens the door to new levels of quality and productivity.
AI as a collaborative partner
It can serve as an intelligent collaborator that augments the expertise of development and QA teams. AI-powered co-pilots can offer context-aware suggestions during the modelling and testing phases, ensuring that best practices are followed, and common pitfalls are avoided. These AI-driven agents can facilitate faster decision-making, reduce manual effort, and improve the accuracy of results, creating a synergistic relationship between human expertise and machine intelligence.

The future of AI in software delivery
As AI continues to evolve, its role in software delivery will expand from supporting specific tasks to orchestrating entire processes. The ultimate vision for AI in software delivery is a seamless integration where models serve as the central source of truth, guiding AI-driven agents to autonomously manage quality, testing, and even code generation. In this future, AI will not just execute predefined tasks but will learn and adapt, improving its effectiveness over time. With AI at the core of quality assurance, software delivery will become more predictable, adaptive, and aligned with business goals—ushering in a new era of quality-driven delivery.
Quality-driven delivery
A model-driven approach addresses many of the challenges organisations face in modern software delivery. By providing a clear and structured framework for defining, designing, and validating software, models ensure that high-quality assets are available at every stage of the delivery process. This alignment between requirements, design, and testing eliminates common bottlenecks, reduces rework, and enhances overall productivity.
Visual models serve as a central repository of knowledge that all teams can use to understand, verify, and build software that meets business expectations. By adopting a model-driven approach, organisations can deliver software more predictably, improve collaboration, and establish a robust foundation for long-term success. This structured methodology not only enhances current delivery processes but also future-proofs organisations for the growing complexity of modern software systems.
Turbocharge software delivery
Our outer loop experts will help you identify symptoms of inner/outer loop misalignment at your enterprise, crafting a roadmap to software delivery productivity and quality.