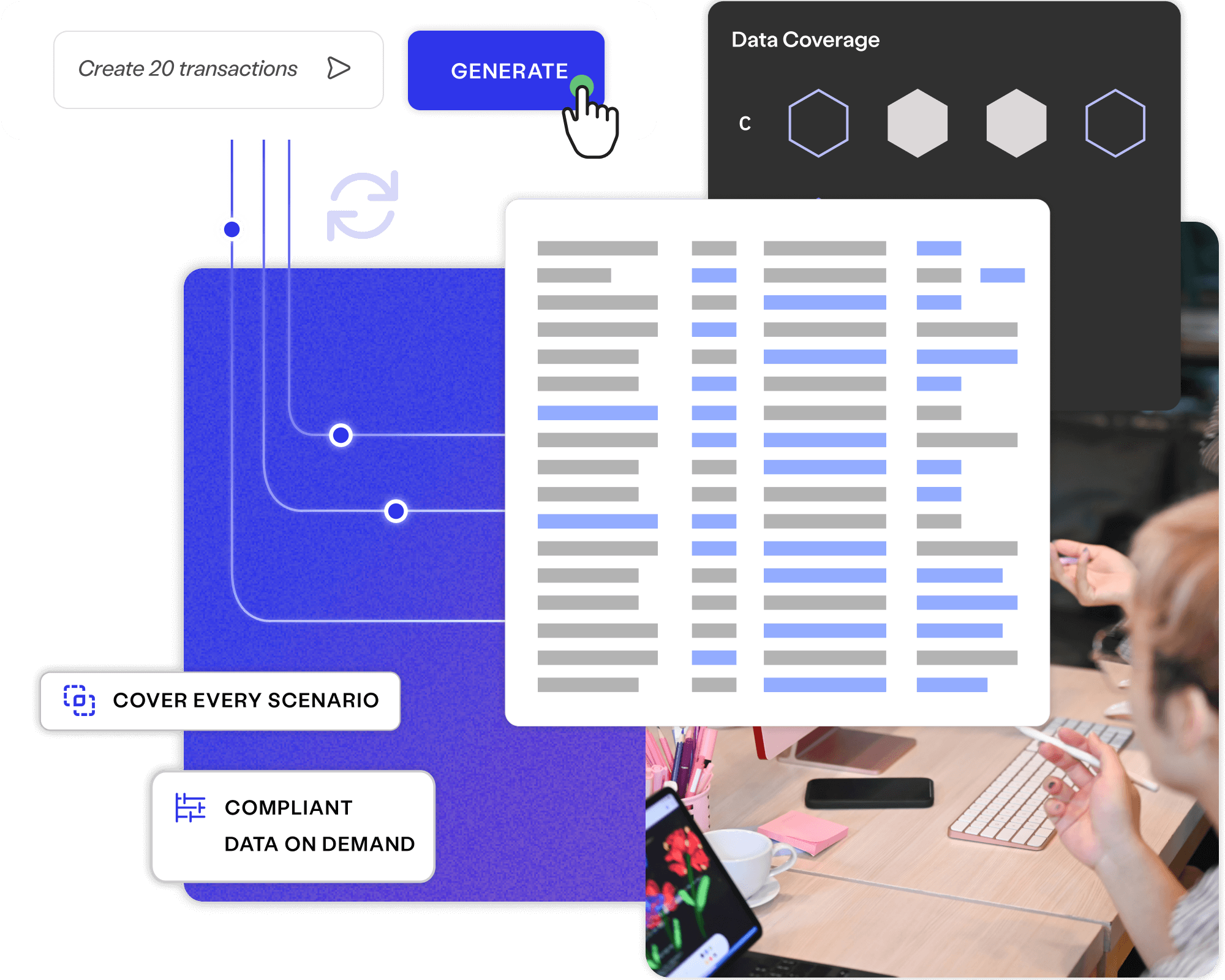
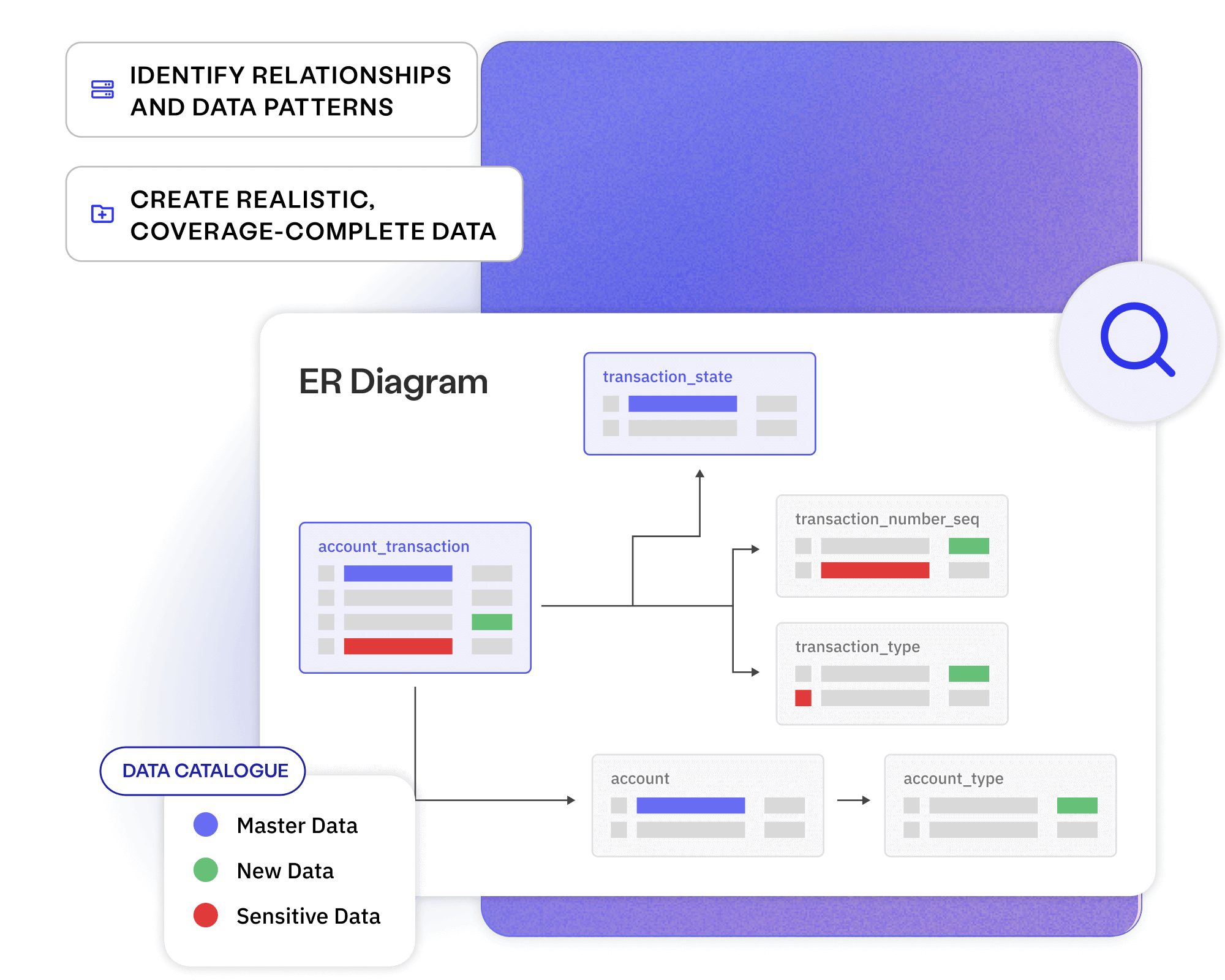
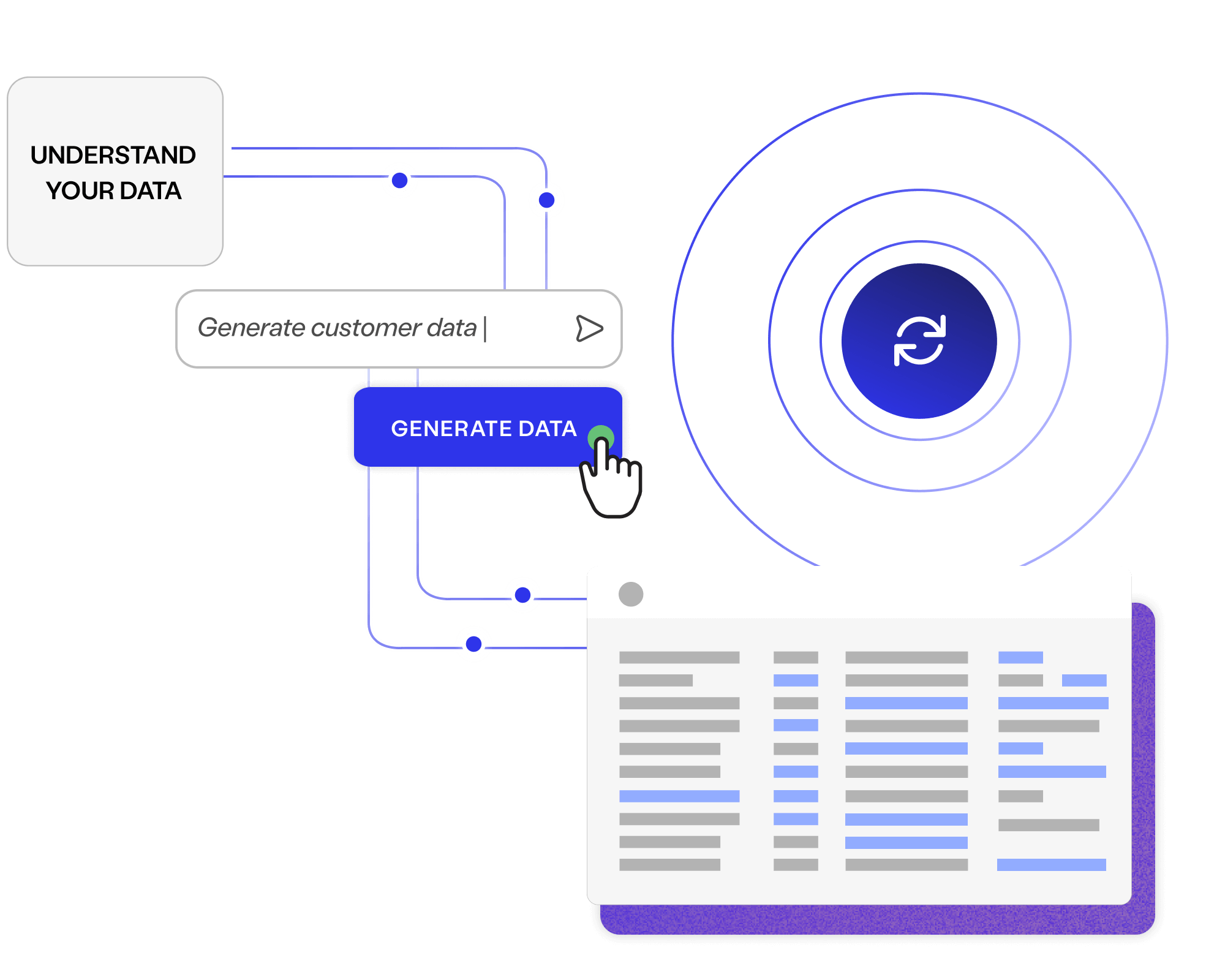
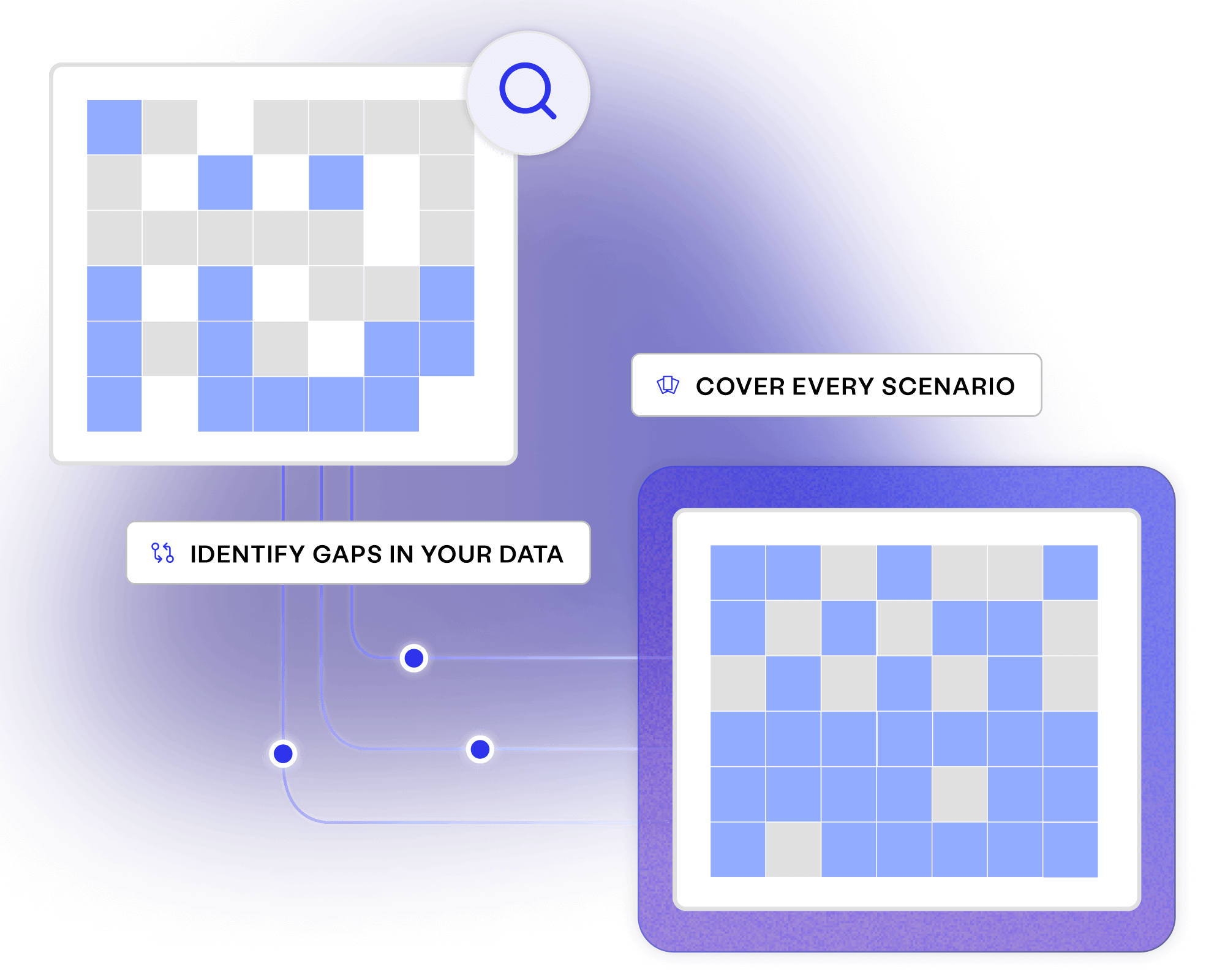
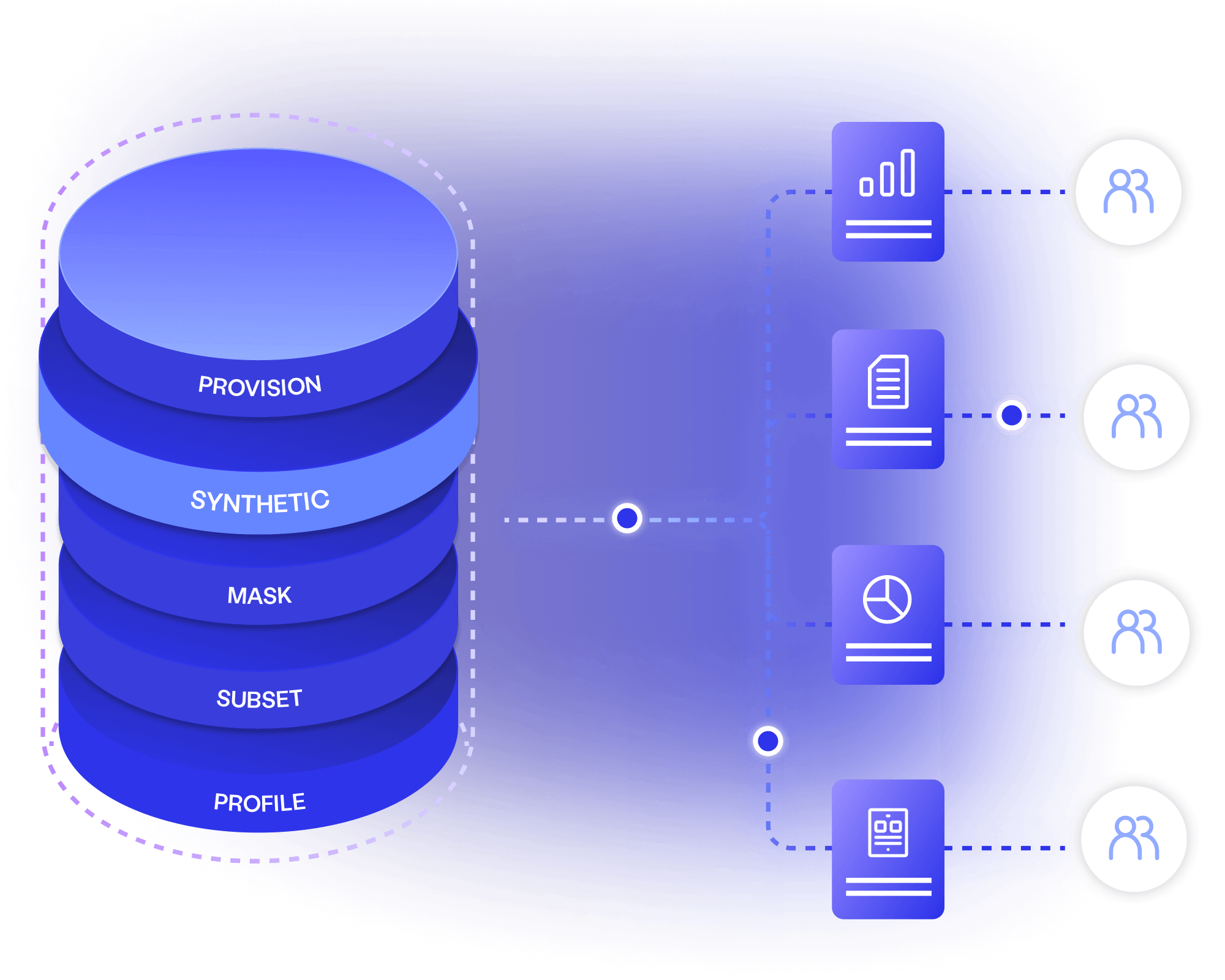
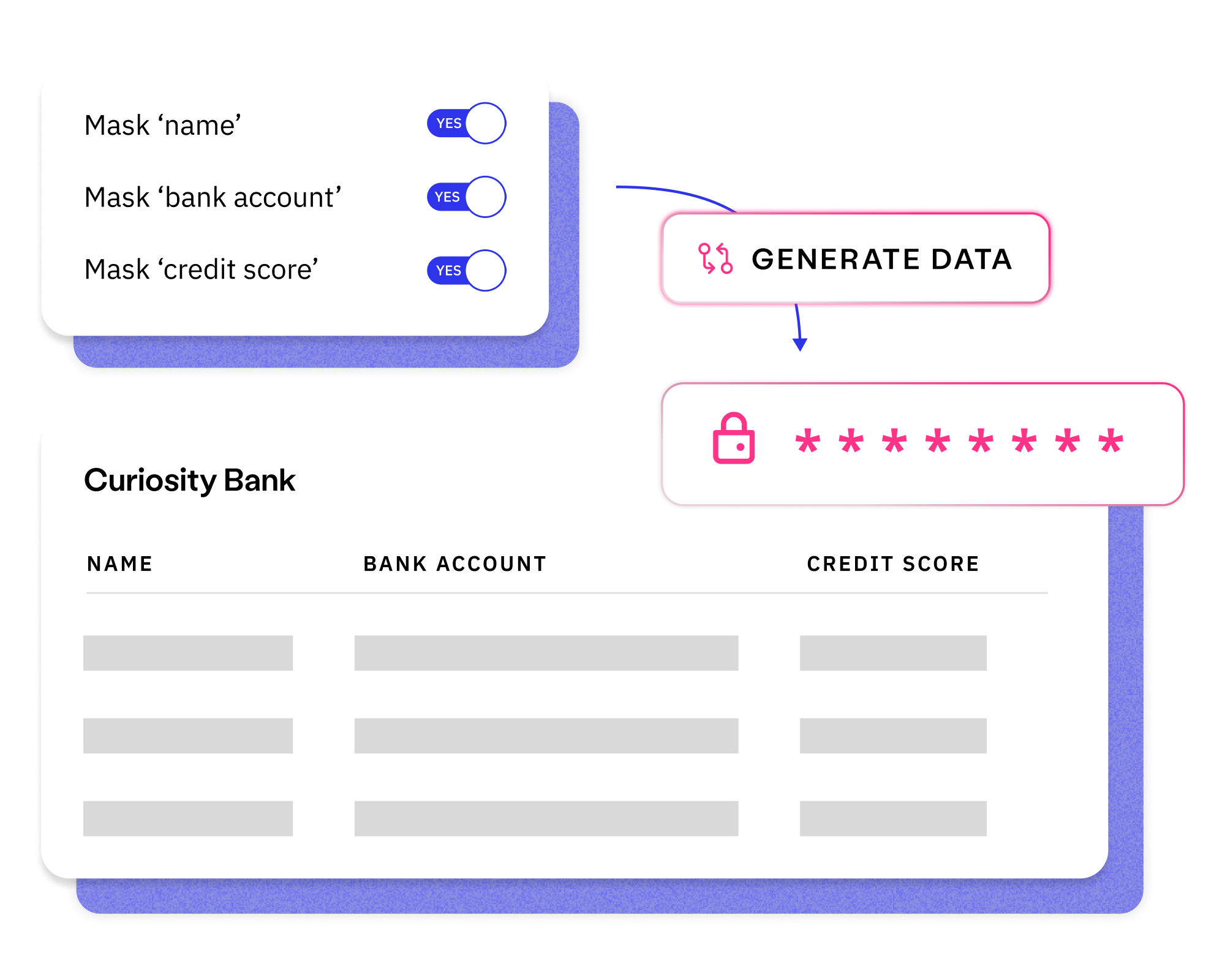
Create fictitious data to cover every user story, test case and business requirement, available on demand to your entire delivery ecosystem.
-
Cover every scenario needed for quality
-
Ensure continuous data availability
-
Replace sensitive data in lower environments