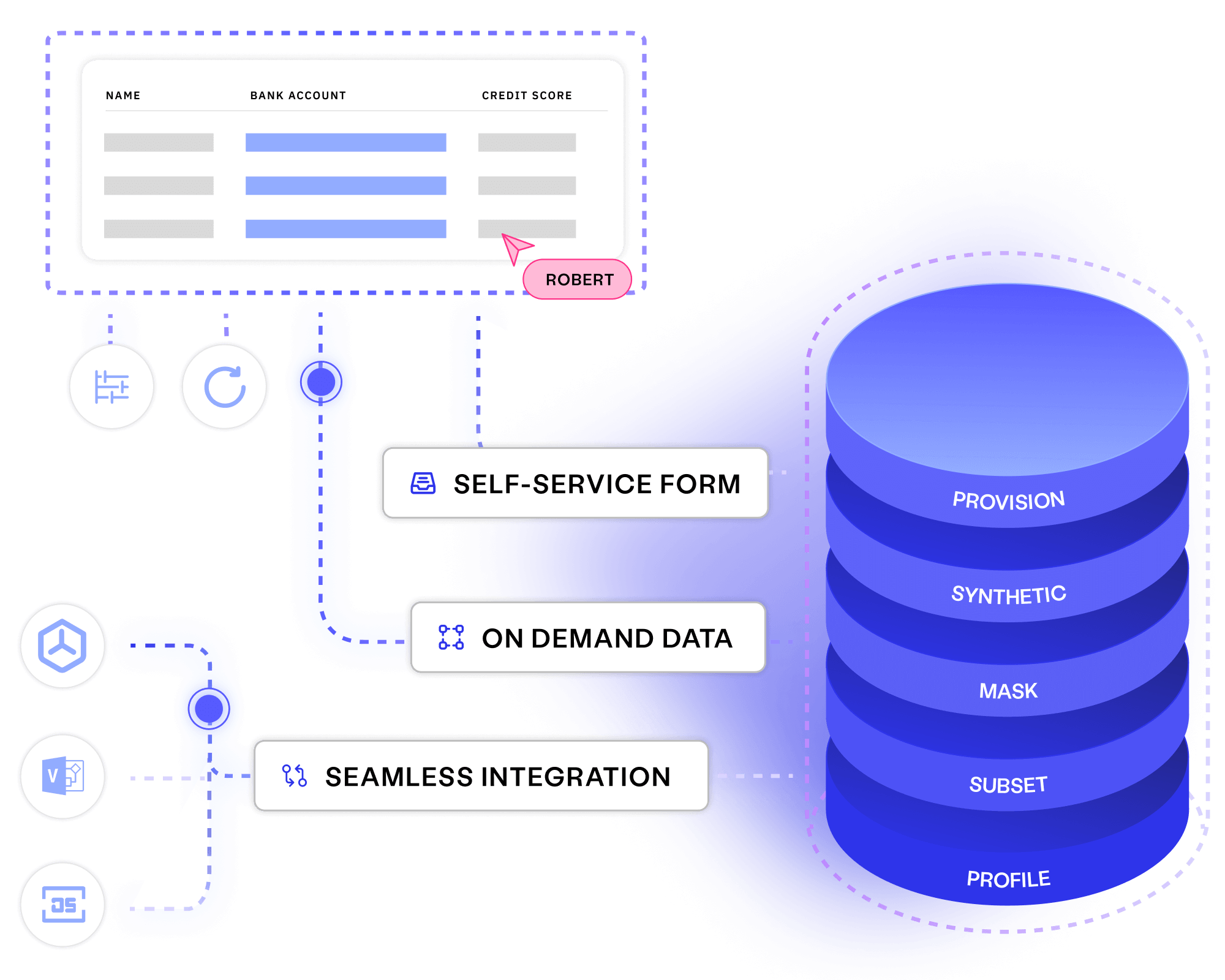
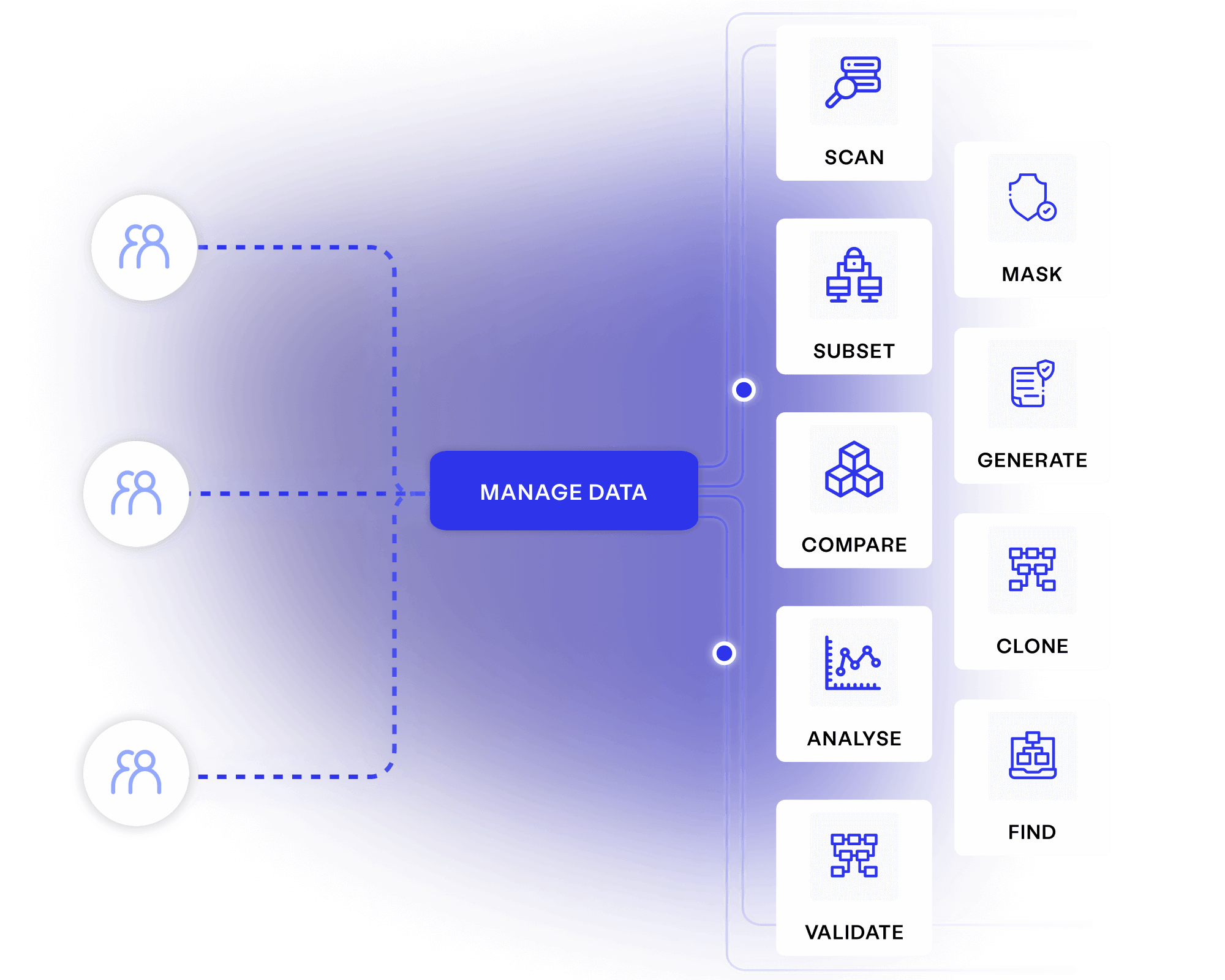
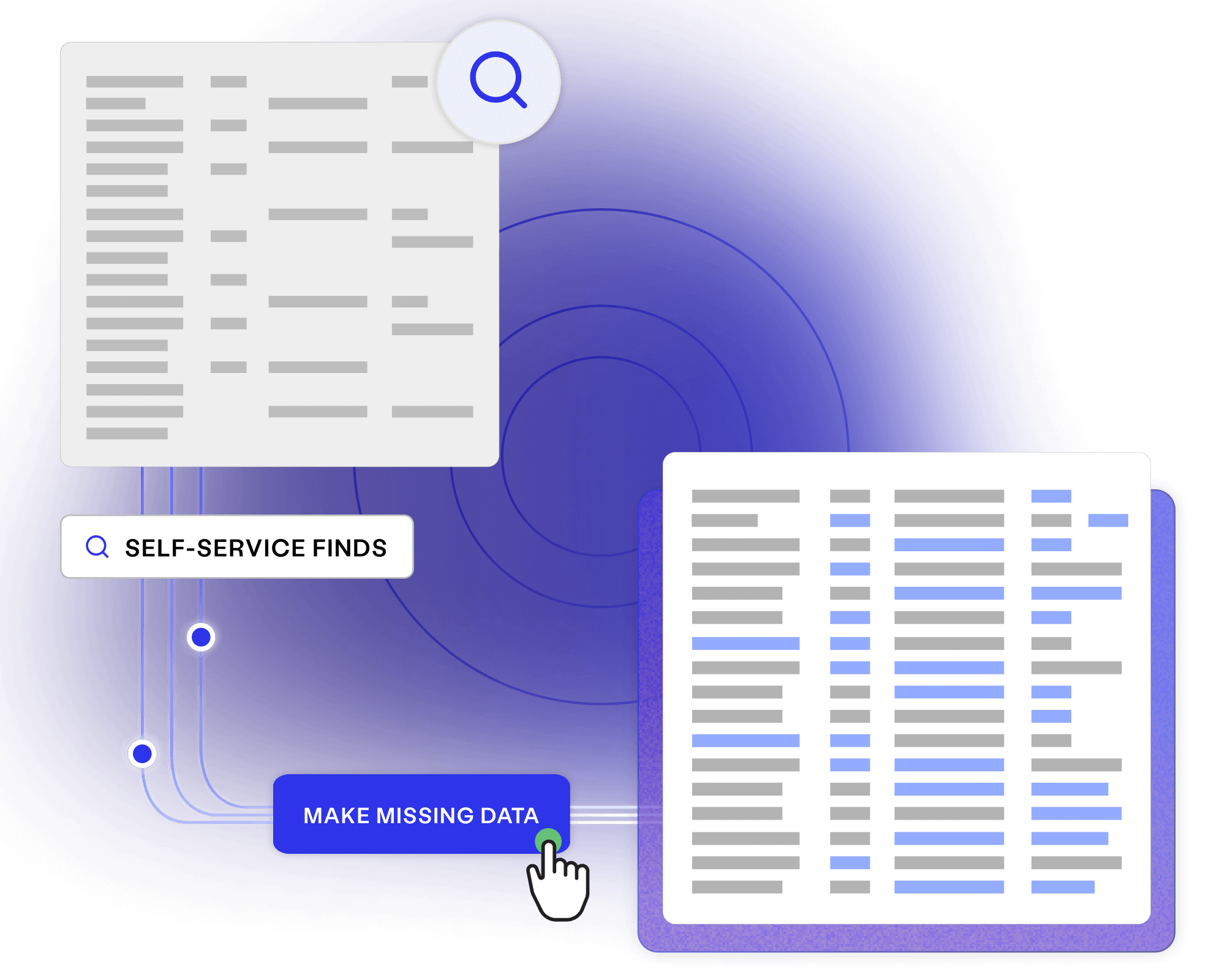
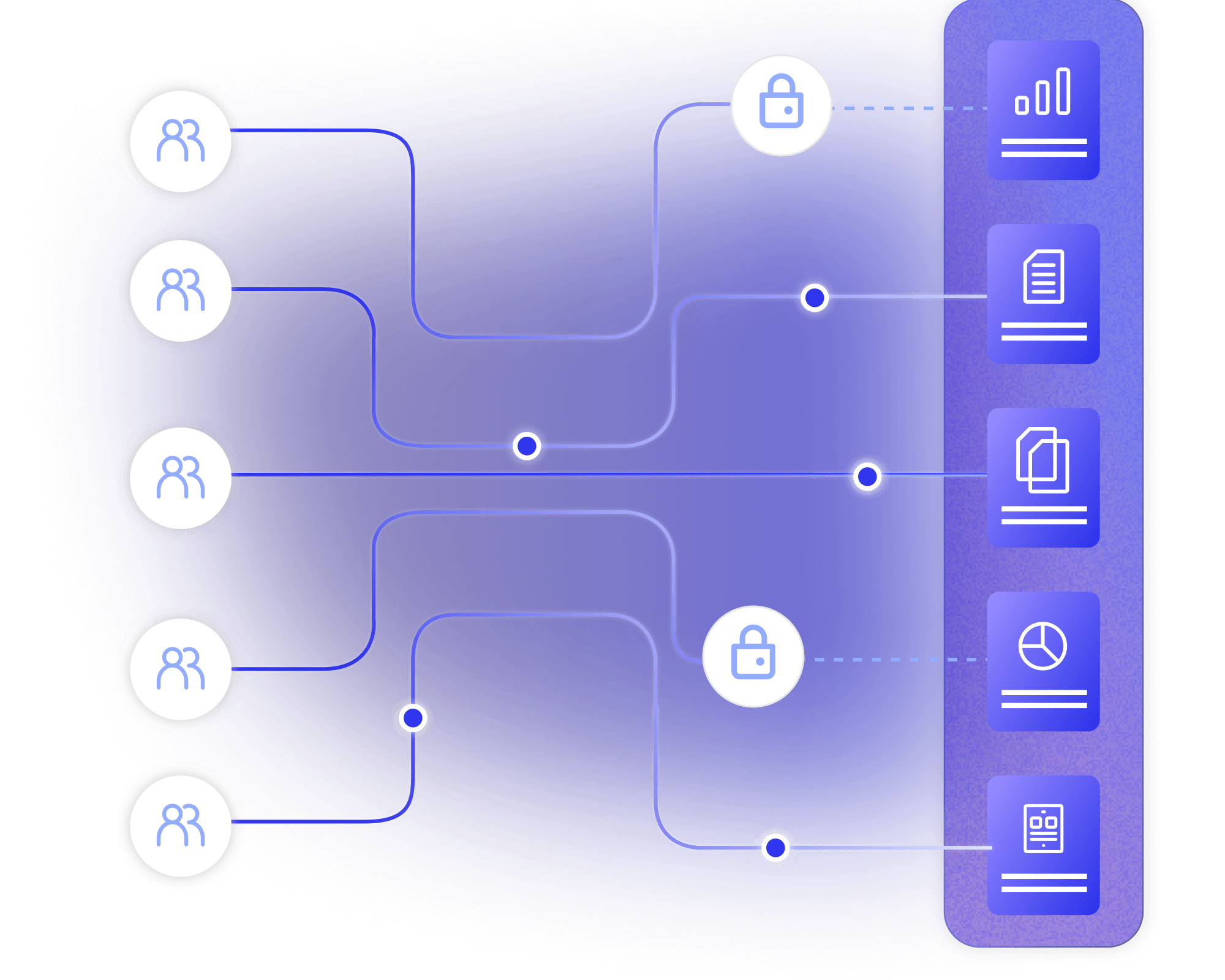
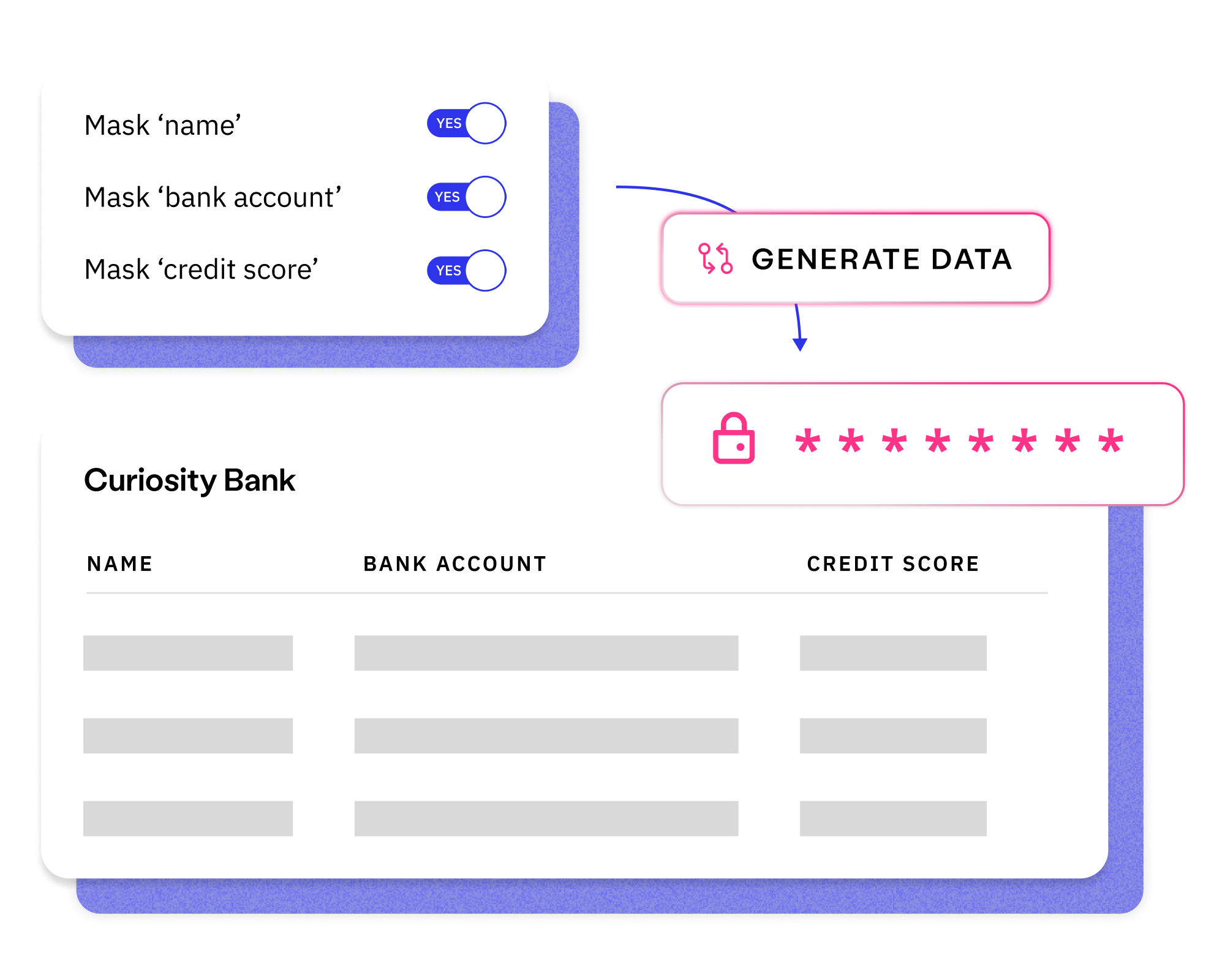
Stop wasting delivery time finding, making and waiting for test data. Provision data using self-service forms, seamless integrations, and an automated test data toolkit.
-
Slash provisioning time and costs
-
Maximise productivity and agility
-
Boost quality and avoid failures