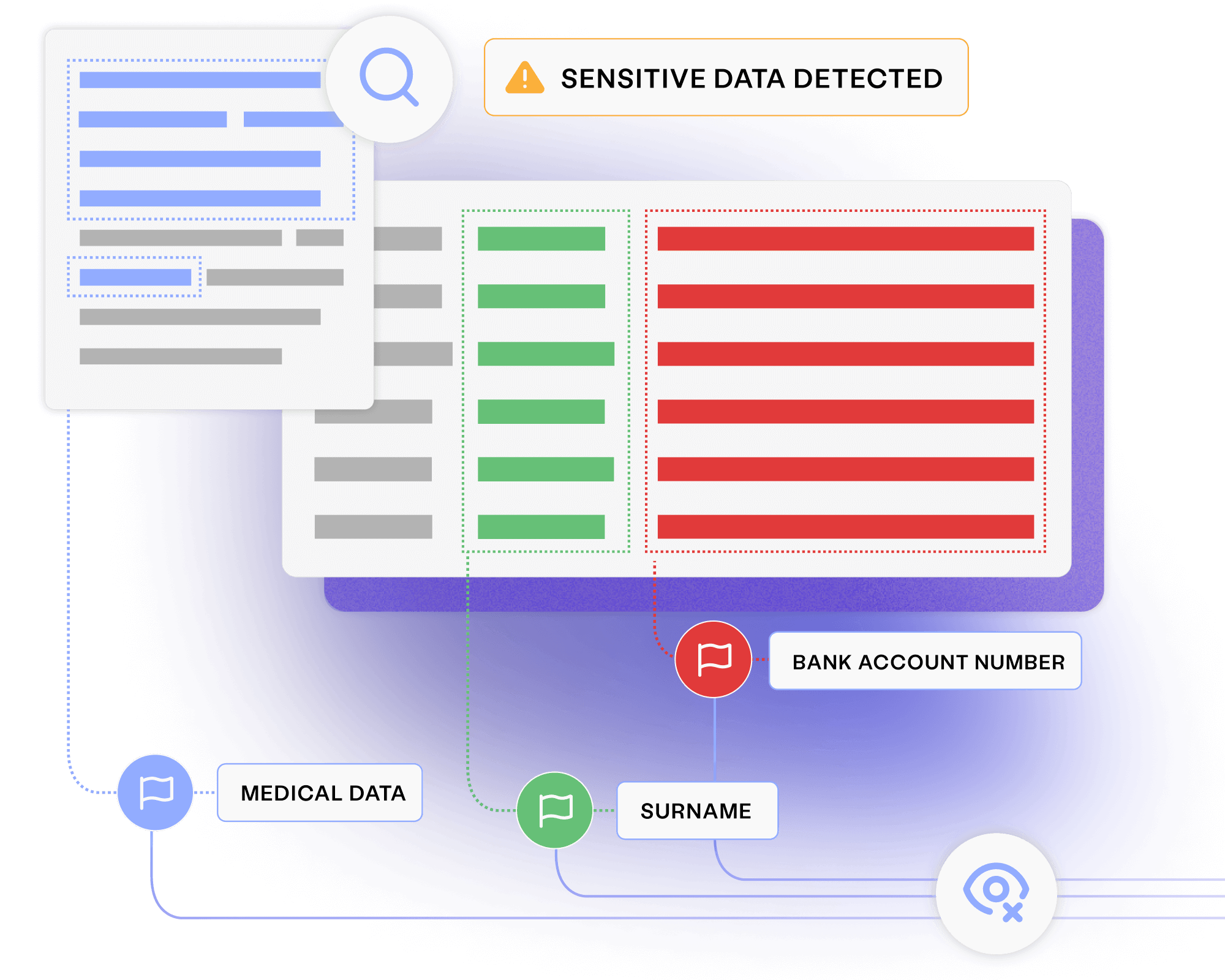
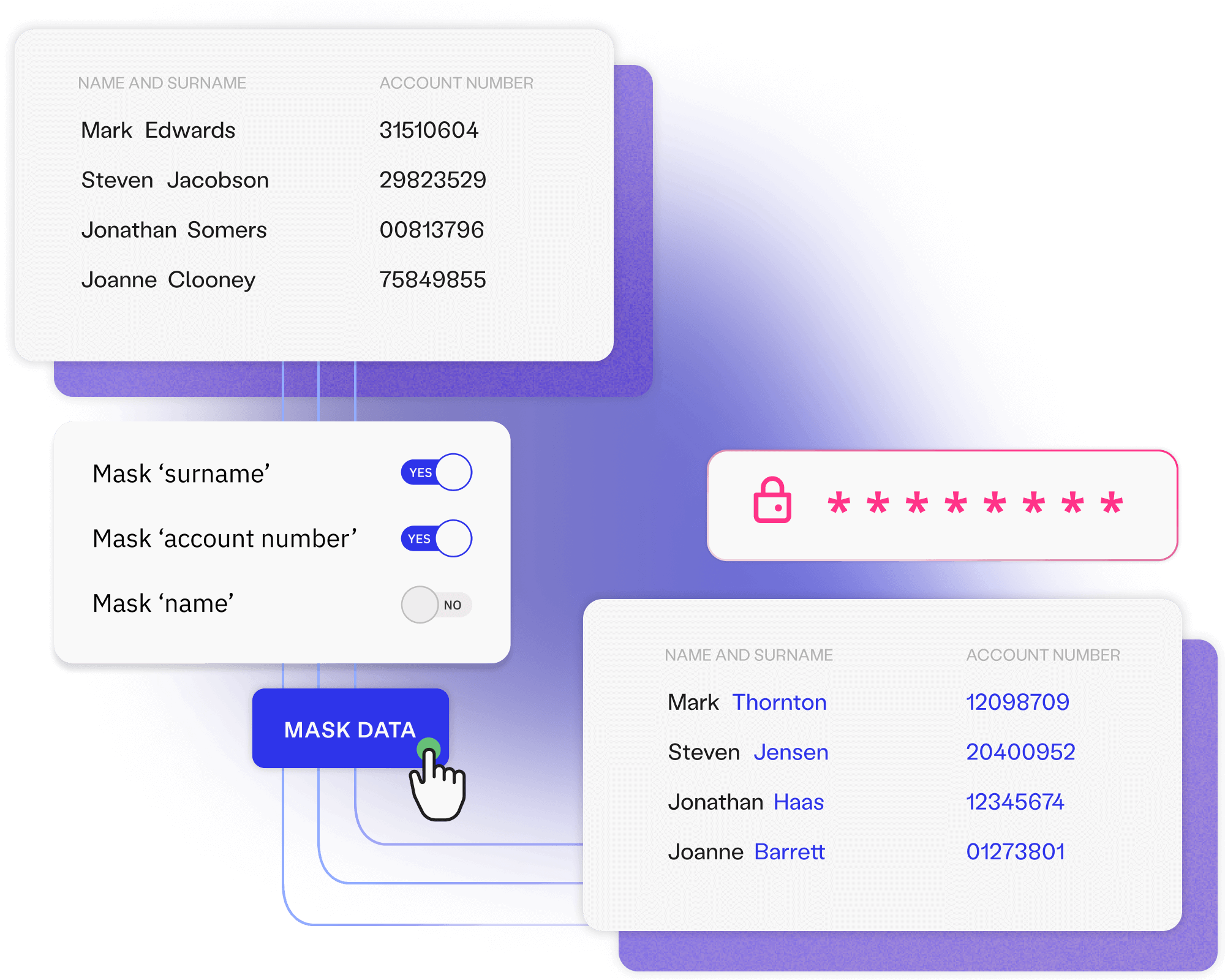
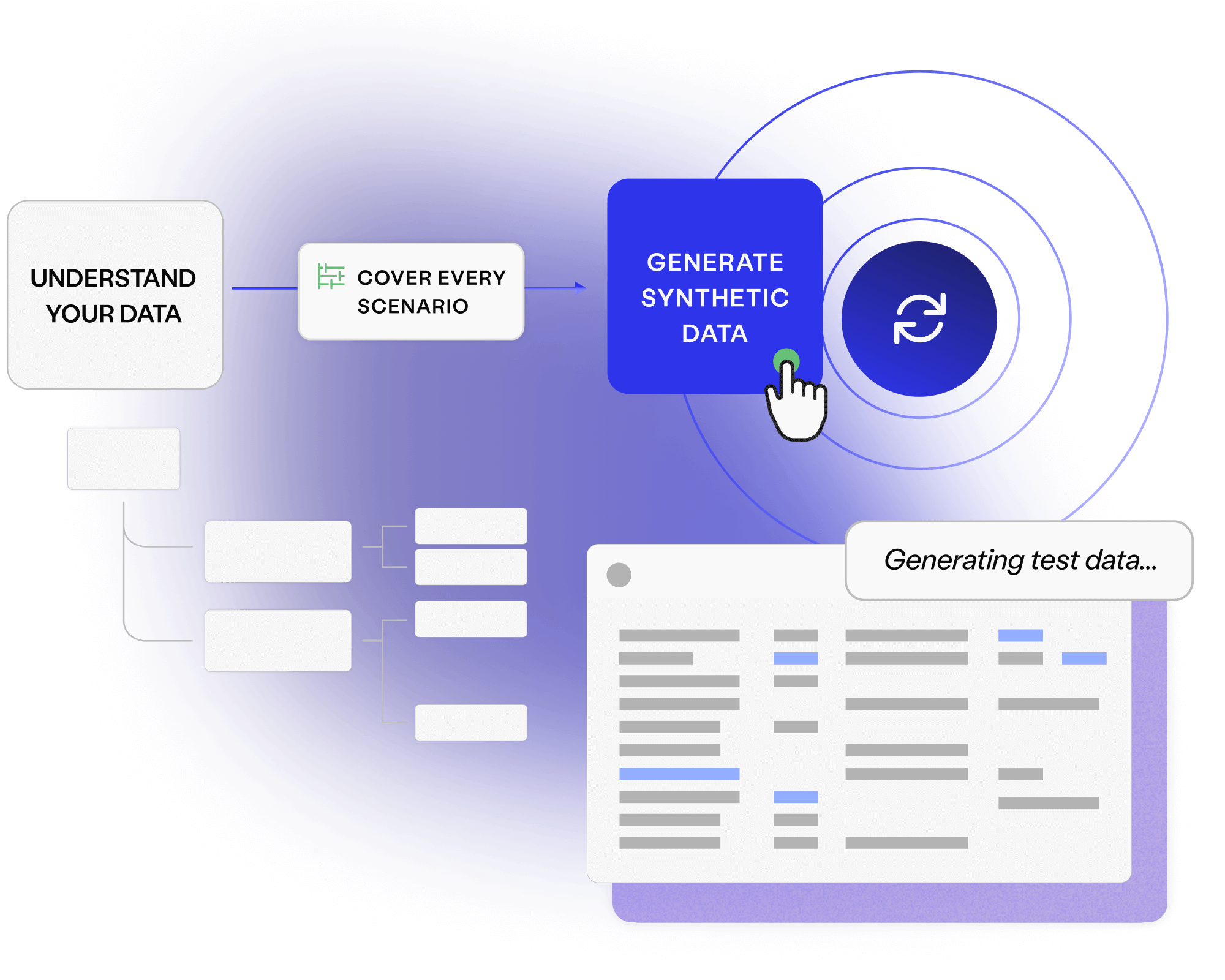
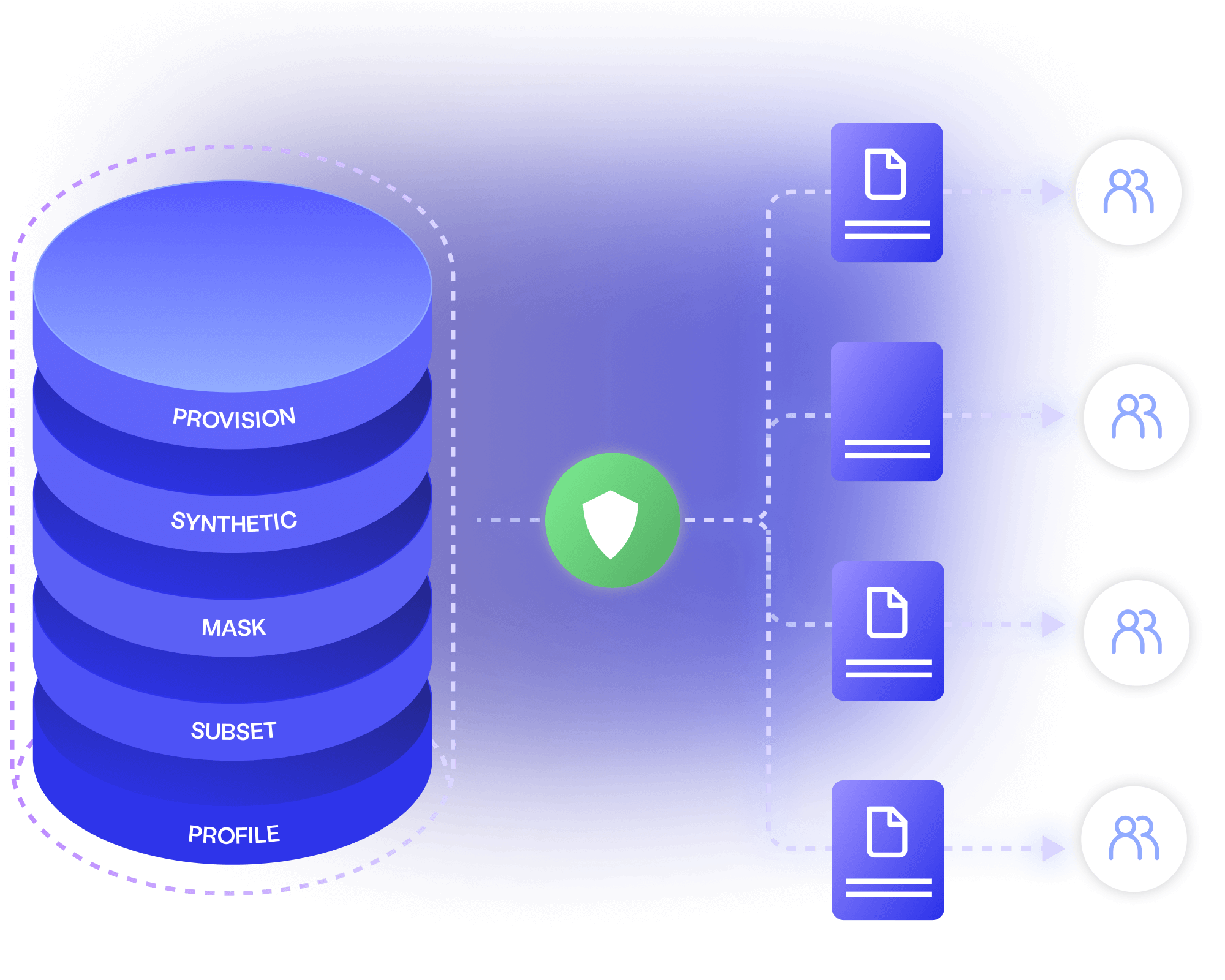
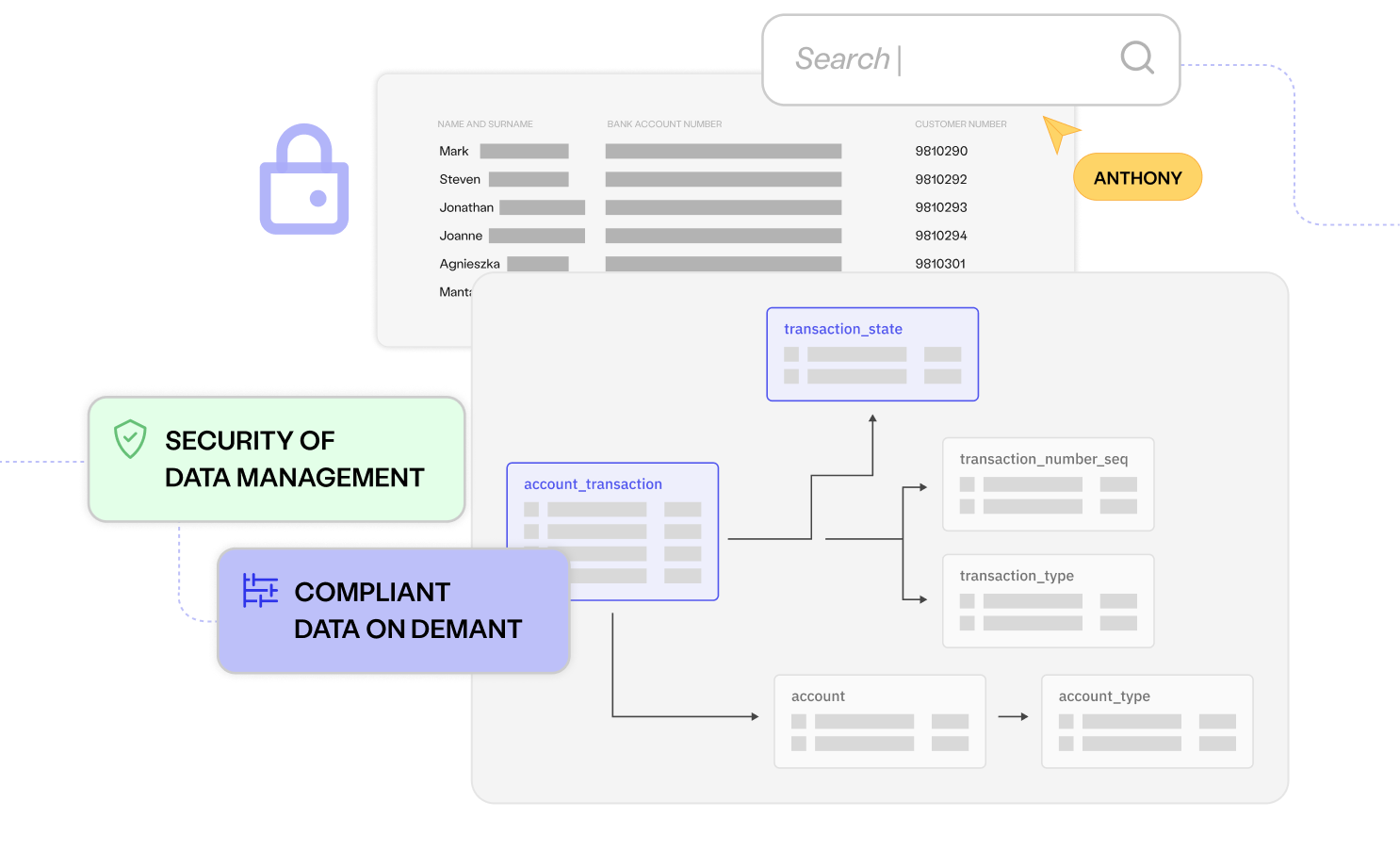
Automatically identify and anonymise sensitive data before it’s provisioned to less-secure environments. Avoid data breaches and ensure regulatory compliance.
-
Eliminate privacy and legislative risks
-
Block PII from reaching lower environments
-
Leave no excuse for using production data