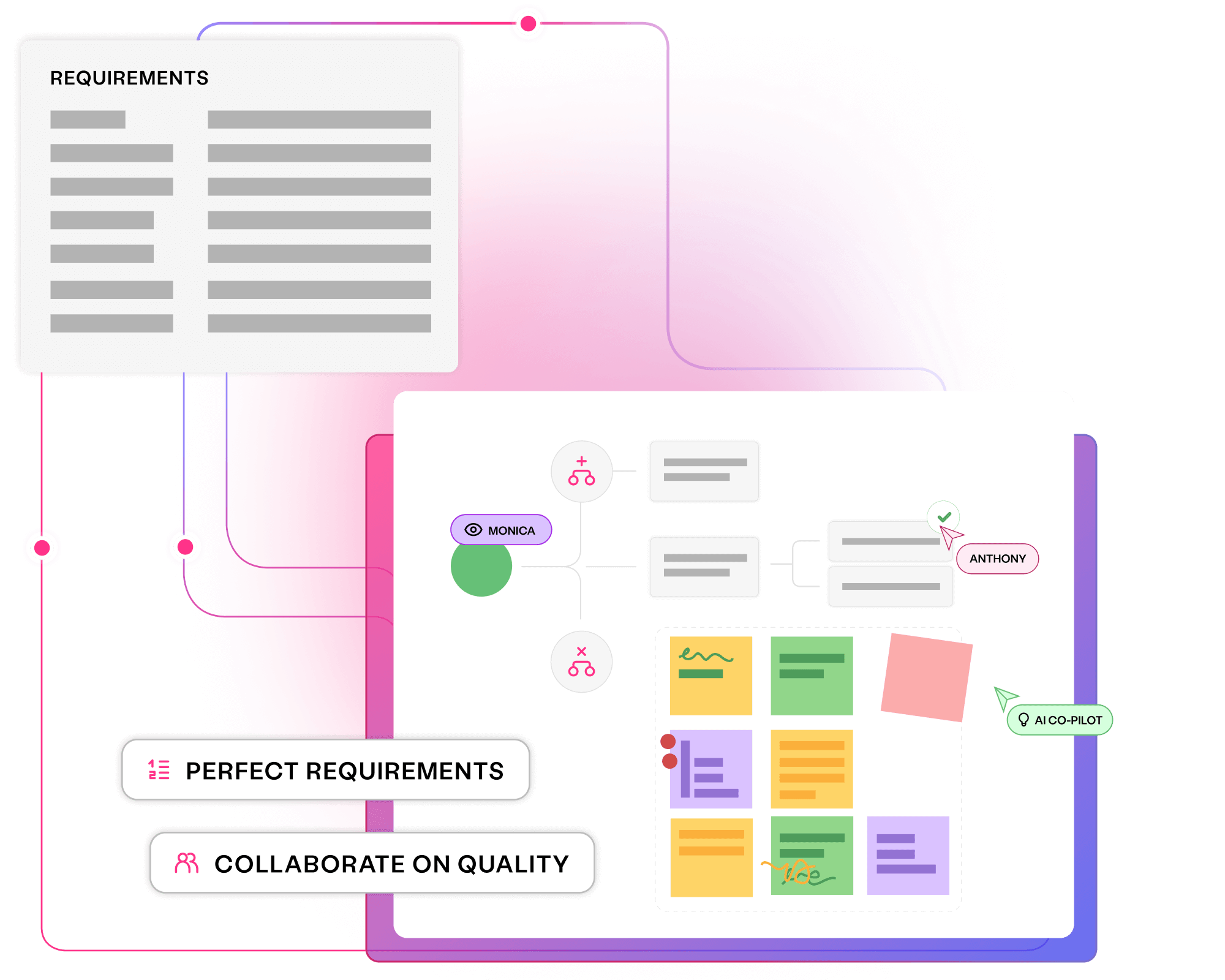
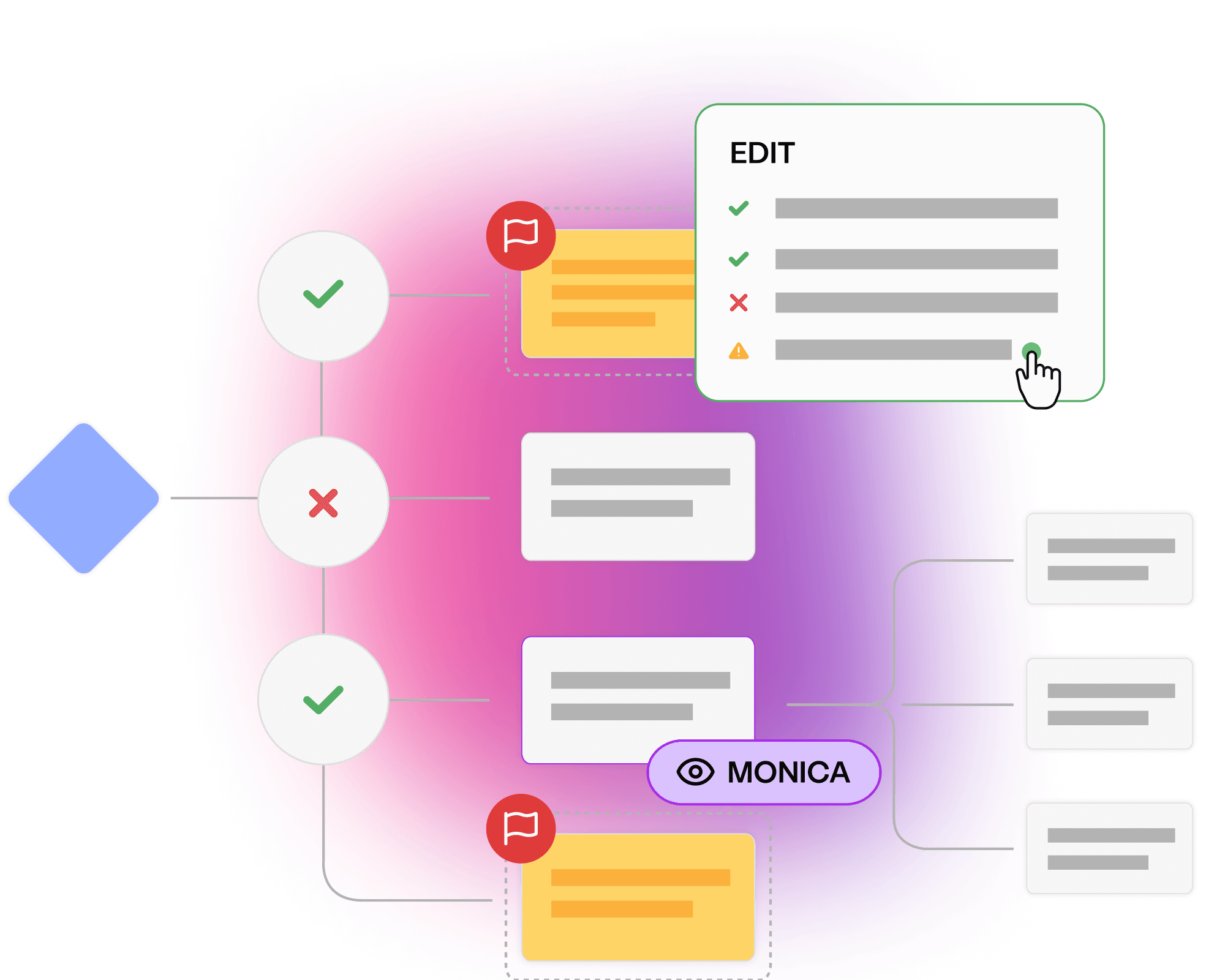
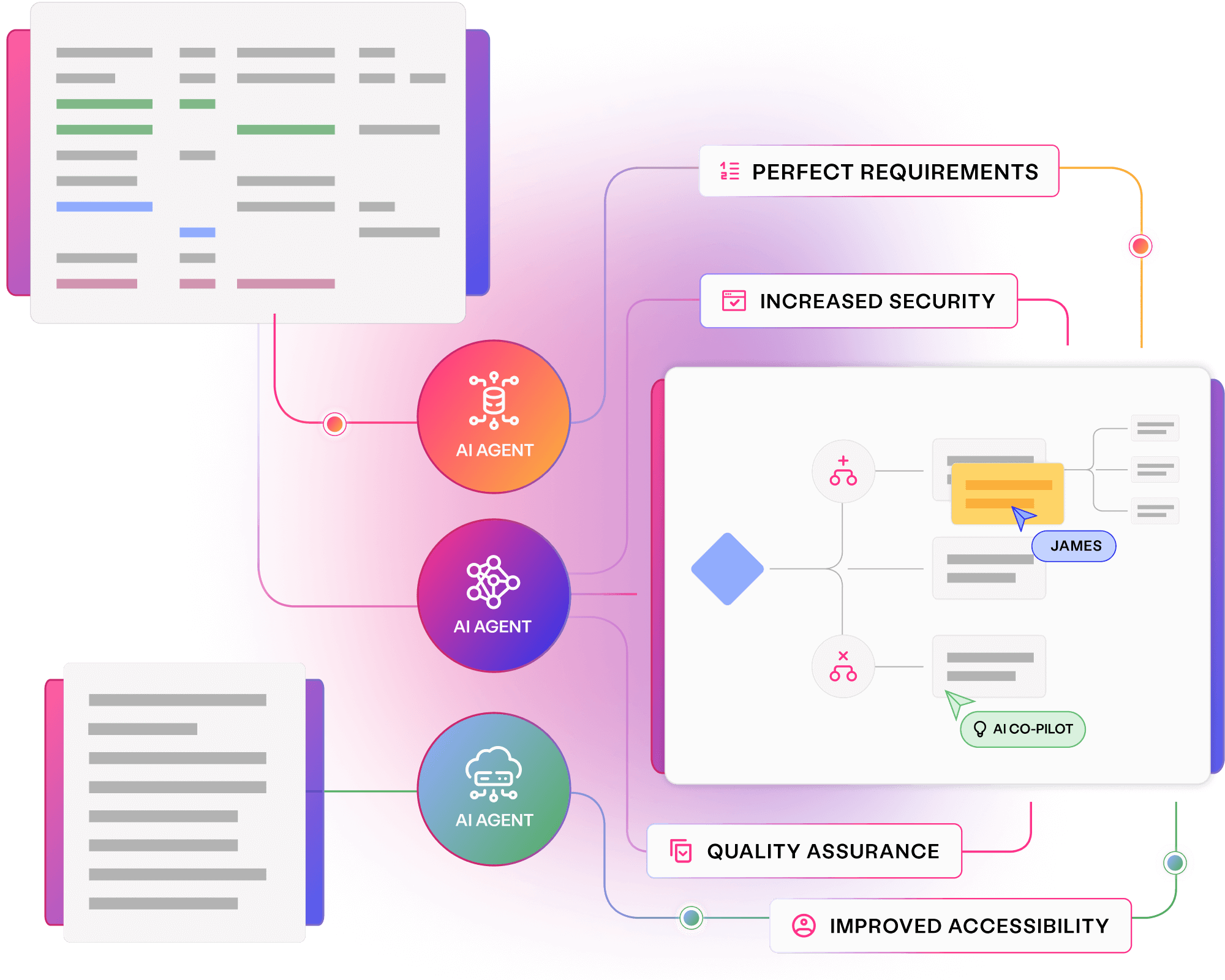
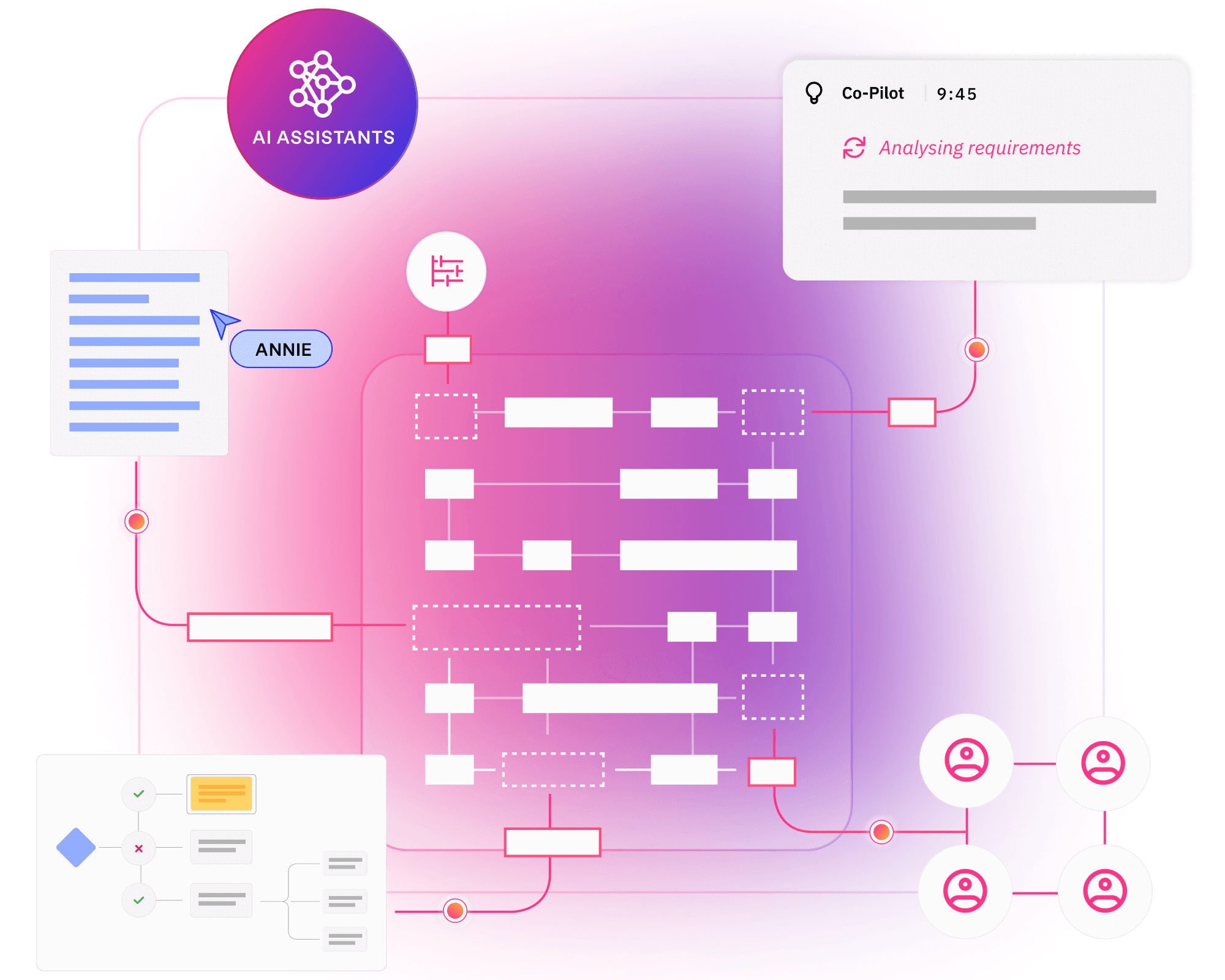
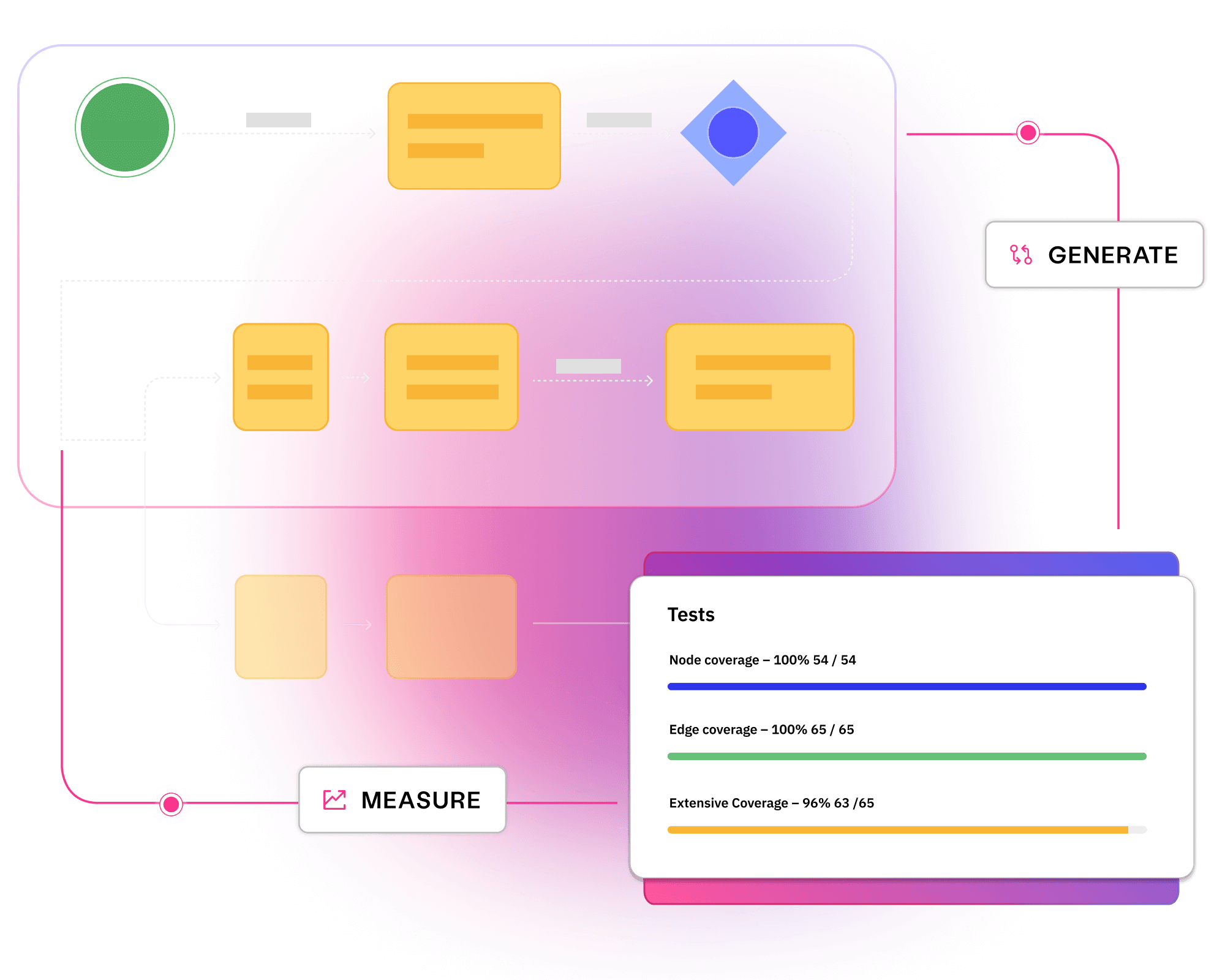
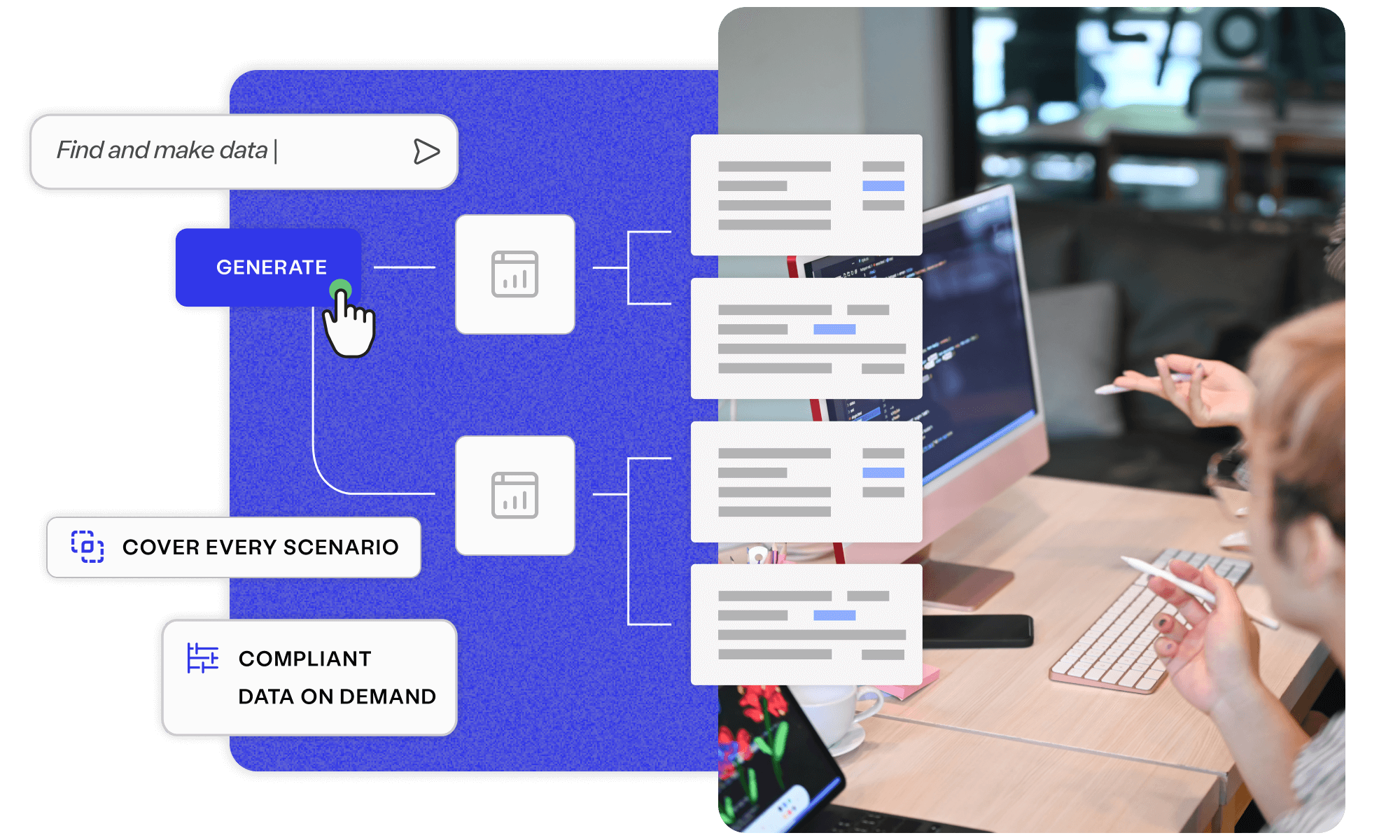
Visualise requirements in clear models to avoid miscommunications, prevent costly bugs, and align every team to quality outcomes.
-
Align stakeholders to quality requirements
-
Prevent bugs and miscommunications
-
Think critically and collaboratively