



Data generation enables organisations to create data of the right variety, density, and volume for different testing and development scenarios, all while avoiding the compliance risks associated with using raw production data.
Creating data from scratch will be familiar to testers and developers, who often produce data when they find that the varied data they need is missing or unavailable. Today, further applications of data generation are emerging, such as the generation of training data sets for AI/ML.
Several factors might lead you to consider adopting a new data generation solution. These include evolving compliance requirements, growing data complexity, and an increasing demand for data across your organisation. In these instances, an automated, proven solution might promise to be more robust and scalable when compared to the ad hoc data creation that occurs manually during testing and development.
This article sets out 28 questions you should ask yourself when considering a new data generation solution. The questions aim to ensure that a data generation solution will be capable of creating fit-for-purpose data at scale. They aim to assess whether a solution will provide the data your teams need, without introducing unwanted complexity, bottlenecks, or overheads.
Extensibility and connectivity
The types of data used at an enterprise are constantly shifting, as teams and systems implement new technologies. This leads to a proliferation in interrelated data types, as legacy components sit alongside new technologies like cloud-based applications and Big Data systems.
Data generation must be capable of creating data consistently across these new and legacy technologies. It should be equipped with an easily extensible range of connectors, as well as a range of techniques for generating data across systems. Otherwise, generation will not scale over time, and will not be future proofed as new technologies are adopted. You might find then be forced back to using copies of production data as your data generation tool cannot generate the data you need.
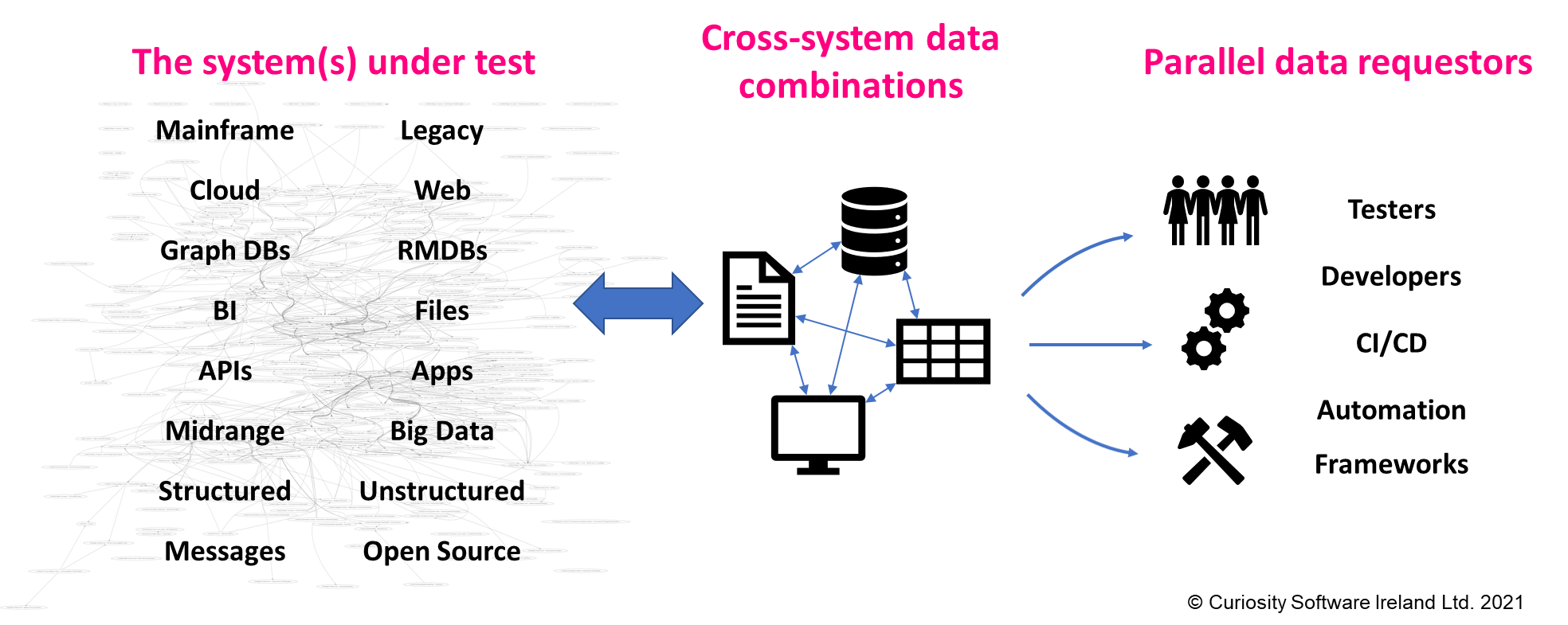
Synthetic data generation must be capable of meeting a proliferation in interrelated data types needed in testing, development and CI/CD.
When considering approaches to data generation, ask yourself:
- Can the generation create data for every type of data used at your organisation today?
- Does the data generation tool provide connectors for generating data into lots of different systems?
- Can it generate data journeys consistently across different systems?
- Does it provide a quick, easy, and standardised methodology for adding new connectors as the types of data you use change?
- Can the data generation create data using a range of techniques, for instance going direct to a database, via a front-end, or via APIs, messages and files?
Ease-of-use and operational efficiency
A common concern with synthetic data generation is that it will be too time-consuming and unreliable when defining data generation for complex data. A data generation tool should therefore be intuitive and easy-to-use, while maximising reusability to boost efficiency.
When considering synthetic data generation, ask yourself:
- Are data generation jobs, rules, and functions easily reusable and combinable?
- How quick, easy, and automated is data analysis, profiling, and modelling?
- Is data analysis easily reusable, for instance from central data dictionaries?
- How quick, easy, and intuitive is it to define data generation functions and rules for complex data?
Integration into DevOps and CI/CD toolchains
In addition to supporting the full range of data types at an organisation, data generation should integrate seamlessly into both manual and automated ways of working. A lack of integration risks creating dependencies and bottlenecks, as data generation will require manual intervention within otherwise automated pipelines.
Synthetic data generation should furthermore be easily combinable with other technologies and techniques for creating and manipulating data. Otherwise, disparate processes for creating and provisioning data will require manual configuration and alignment. Running these complex, interrelated processes manually in turn risks creating inconsistent and misaligned data sets, undermining effective testing and development.
When deciding techniques for synthetic test data generation, ask yourself:
- Is the generation an open technology, capable of integrating with every tool, automated process, and manual process? This should include automated technologies like CI/CD pipelines and test automation frameworks, as well as the manual processes performed by teams at your organisation.
- Does generation integrate with all other requisite data management processes (such as masking, allocation, and subsetting)?
Data automation vs data management
To ensure scalability and adoption, data generation should maximise automation and reusability, while minimising repetitive manual configuration.
Manual approaches and narrowly defined (non-event-driven) automation are typically limited in scope, requiring fresh configuration for each subtly different scenario. They further require rework and reconfiguration as data, scenarios, systems, and requests change. This continuous manual intervention is not sustainable, given the continuously increasing demand for data demand at enterprises today.
When creating a strategy for synthetic data generation, ask yourself:
- Can data generation form part of a truly automated service, or does it remain within the test data management paradigm?
- Can generation be triggered on demand, meaning on-the-fly?
- Are previously configured data generation jobs flexible, reusable, and parameterizable?
- Can manual and automated data requesters parameterise and run the jobs on-the-fly?
- Is a pre-configured generation job capable of handling differences in data requests (parameters or inputs from the requestor)?
- Is data generation capable of handling changes over time in production data, environments, test scenarios, and more?
Data complexity
Data generation does not just need to create data for numerous interrelated data types; the logic that must be reflected in that data can also be immensely sophisticated.
This includes the logic and structure of common types of data, such as the varying logic and syntax for creating different types of Social Security Number. At the same time, accurate data for testing and development must reflect and respect system logic, for instance reflecting temporal trends and sequences.
When deciding an approach for synthetic data generation, ask yourself:
- Can generation reflect complex logic, for instance reflecting a series of events? For instance, if data is generated upstream, can the generated value easily feed into a function that generates data simultaneously into a downstream system?
- Is a comprehensive set of functions provided, including functions for generating sophisticated data like IBAN numbers?
- Can generation be set to generate data for different regions and geographies, reflecting the differences in syntax and data across states and countries?
- How easy is it to customise functions and add new ones?
- How easy is it to combine functions?
- Are consistent journeys easy to generate, for instance using visual techniques?
Fit-for-purpose data
Today, data is required for a wide range of different purposes and scenarios. Testing and development, for instance, requires data of different volumes, density, and variety. Functional testing, for instance, might require high-variety data that’s of lower volumes than the data needed in stress testing, while unit testing and smoke testing will require different data sets yet again.
Generating data of the wrong volume or contents will undermine the accuracy and rigour of testing and development, while introducing bottlenecks. Meanwhile, different data sets must be kept up-to-date, including aligning data for different versions of system components.
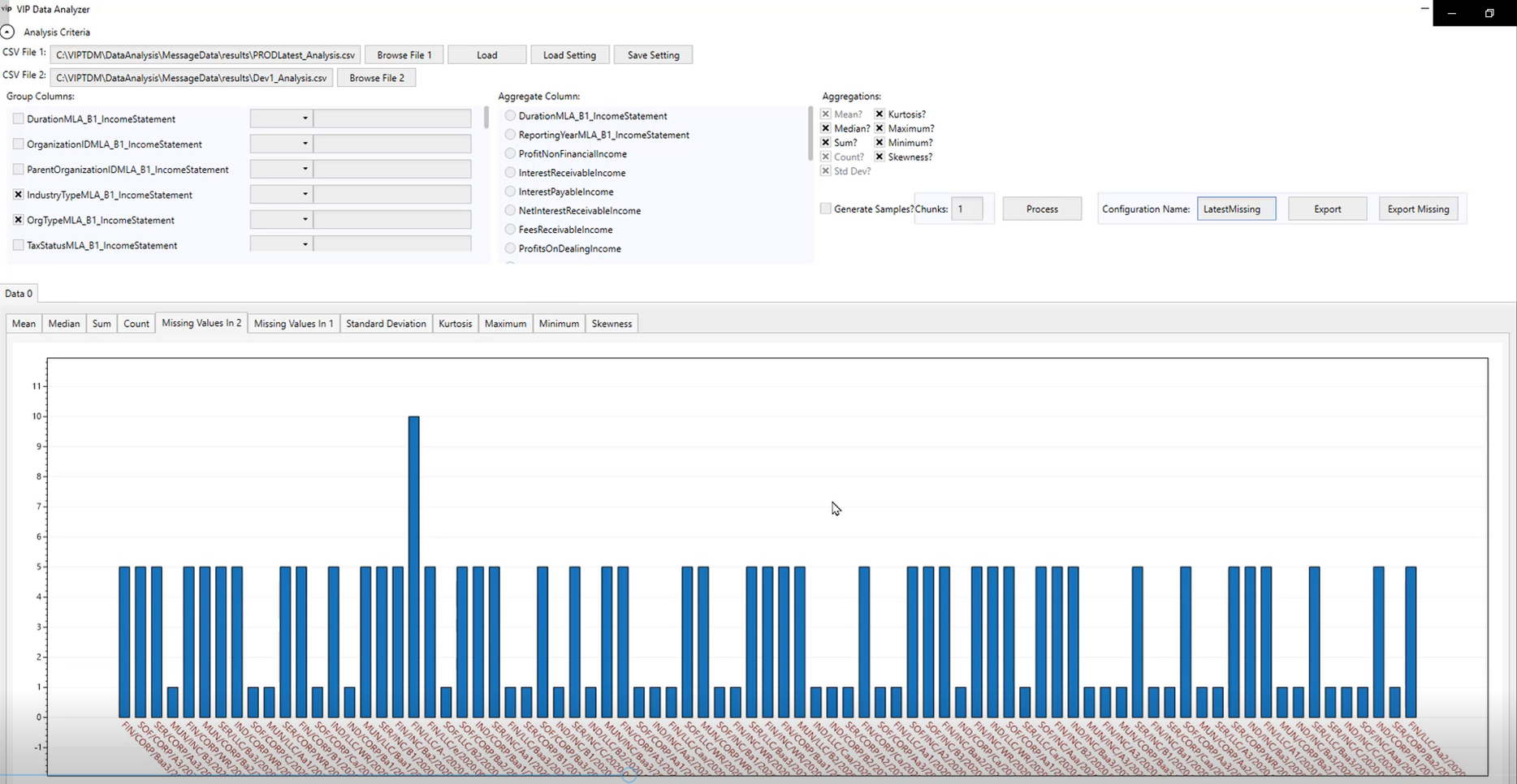
Data generation should be informed by granular analysis, such as data comparisons, coverage analysis, density analysis and kurtosis.
When deciding on an approach to synthetic data generation, ask yourself:
- Can data generation be informed by a range of different types of analysis and data modelling?
- Can data generation be based on coverage analysis, creating “covered” data sets?
- Can generation be based on comparisons between data and environments?
- Can generation be based on granular data analysis, such as density analysis and kurtosis?
- Can the analysis be re-run automatically, updating jobs as data and systems change?
Picking the right data generation solution
The types of data and integrated technologies used at enterprises continues to grow ever-more complex, while the constant need for varied data is growing more demanding across teams and frameworks. Meanwhile, compliance and data privacy requirements continue to evolve.
Automatically generating fictitious data for a range of different testing and data scenarios offers to remove data bottlenecks, while avoiding the use of raw production data in non-production environments.
Any such solution must be scalable and robust, capable of quickly generating data that is equal in complexity to your systems and development needs. The 28 questions set out above are intended to help you identify such a solution.


