In today's fast-paced software development world, one thing is clear: data is critical. But managing test data can be a nightmare. Outdated, manual processes slow everything down, leading to delays, data bottlenecks, and ultimately, frustration.
Self-driving test data leverages AI to transform test data management into an automated, seamless process which anyone can pick up. In this blog, we’ll dive into what this means for the future of Enterprise Test Data and how it’s set to revolutionise software delivery.
The old way isn’t cutting it any more
Traditional test data management comes with a long list of challenges:
- Manual bottlenecks: It’s slow, labour-intensive, and requires deep technical expertise.
- Compliance headaches: With data privacy laws like GDPR, ensuring compliance can feel like an impossible task.
- Scalability struggles: Meeting the increasing demand for more data, faster, just isn’t feasible without a new approach.
The common action we often see organisations (wrongly) apply is quick fixes:
- Testing takes too long? Add automation.
- Releases are delayed? Hire more developers.
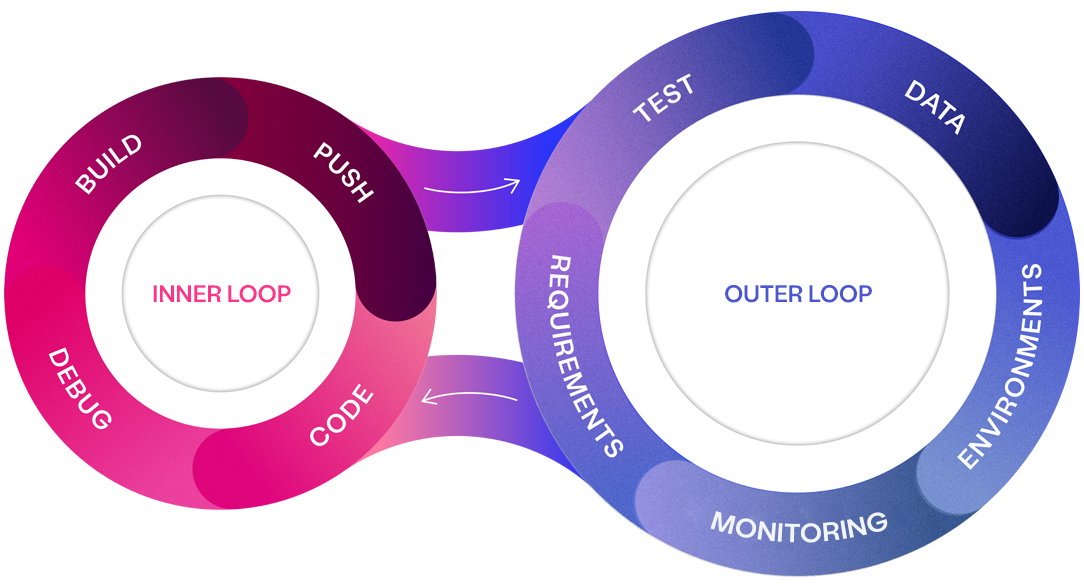
But these are just band-aid solutions. They don’t address the root cause: too much focus on developer productivity (the inner loop) and not enough on the outer loop—the things that surround coding, like test data, environments, and requirements.

The impact of that is over 50% of all IT projects fail, and when they are successful, IT projects are plagued with low-quality software and delayed releases. Test data is a big part of the problem. When data is slow, inaccurate, or unavailable, everything grinds to a halt.
The future of test data on autopilot
Think of self-driving test data as the autonomous car of the test data world. It uses AI to automatically understand your data needs, generate and deliver the right data on demand, and ensure everything is compliant—without the need for manual intervention.
Imagine this: You describe the data you need in plain English, and AI finds and delivers it instantly. No more waiting days (or weeks) for test data. Your teams can keep coding, testing, and delivering, uninterrupted.
We are firm believers that AI will be the future of the test data industry. At Curiosity, we are building towards that future, and we're excited to share of our latest product updates on the path to an AI future for test data.
See the future of test data
Watch our webinar to learn how you can ensure "Right Data, Right Place, Right Time" across your organisation to boost productivity, enhance quality, and streamline your software delivery process.


How AI powers self-driving test data
Let’s break down how AI is already transforming the way we think about and generate test data.
AI-Accelerated Data Glossary: Understanding an enterprise's complex data ecosystem can be overwhelming. Curiosity's Enterprise Test Data AI builds a comprehensive data glossary, enabling teams to quickly understand, query, and summarize their data.
Virtual Data Engineer: AI takes plain English requests and translates them into real-time data generation. No technical knowledge required. This feature ensures on-the-fly data provisioning.
AI-Driven Discovery: AI-driven discovery helps you automatically map your data, ensuring regulatory compliance and reducing the risks associated with data privacy.
Chat to Data: A global co-pilot for data, enabling users to interact with the ETD platform through a natural language interface, allowing for contextual question answering. By facilitating easier exploration and understanding of complex data environments, this enhances productivity and enables users to make informed decisions quickly.
AI-Enhanced Visual Model Generation: AI is used to generate enriched visual models to create comprehensive data representations, which can then be used to create covered sets of data representing the scenarios needed. This provides a more detailed and insightful view of data variations, supporting effective software delivery by ensuring that all possible scenarios of data are considered and delivered in the right places.
What’s next?
At Curiosity, we see self-driving test data as a journey, and we’re just getting started. Currently, we’re at Level 1—the Co-Pilot Era, where AI assists in test data management through automation and natural language interfaces. But this is just the beginning. Here’s what’s next on our roadmap:
Level 2: Autonomous Test Data Management
In Level 2, AI will evolve from being a co-pilot to an autonomous driver. This means the platform will not only assist, but also predict and proactively generate the test data you need before you even ask for it. AI will understand patterns in your testing requirements, making the test data provisioning process even faster and more efficient. At this stage, AI will handle much of the decision-making related to data generation, compliance, and provisioning.
Level 3: Fully Self-Driving Data Ecosystem
The ultimate goal is a fully self-driving data ecosystem. Here, AI will manage all aspects of test data across the enterprise autonomously, providing data not just for testing but for any part of the software delivery lifecycle—development, testing, and production environments. This stage will enable true end-to-end automation, where human intervention is almost entirely removed from data provisioning.
Self-driving test data is the future
We firmly believe that self-driving test data is the future of the test data industry. It doesn’t just address the bottlenecks that plague traditional data management—it completely removes them. Here’s why it matters:
- Faster Releases: With AI handling data provisioning, you’re no longer waiting on data to move forward. This means faster software releases and happier customers.
- Better Quality: With the right data available at the right time, you reduce bugs, improve software quality, and boost overall productivity.
- Increased Compliance: AI ensures that all your test data is compliant with regulations like GDPR, so you can move fast without sacrificing security or privacy.
At Curiosity, we’re building the future of test data, and we’re excited to share some of our latest updates on the path to an AI-driven future for test data.
Eliminate test data bottlenecks
Discover Curiosity's complete test data toolkit and solve all your enterprise's test data needs, providing rich and compliant data on demand