



Today, there is a greater-than-ever need for parallelisation in testing and development. “Agile” and iterative delivery practices hinge on teams working in parallel, as otherwise iterations become mini-waterfalls as one team waits for another to finish.
DevOps and CI/CD likewise rely on parallel processes, while part of the speed gains offered by test automation lie in its ability to run parallelised tests. Certain types of testing, like load testing, are furthermore impossible if high volumes of tests cannot be run in parallel.
Too often, test data undermines parallelisation
In spite of its importance, the parallelisation of tests and teams is frequently undermined by a lack of autonomy (or independence) in non-production environments and data. This is reflected in perennial frustrations that testers and developers experience, like:
- “My automated test failed because another test in the suite used up or edited the data it needs”.
- “I need a rare customer type with this history to run this high-priority test. However, another tester has deleted the customer from the database and a refresh is not due for weeks.”
- “We cannot run our tests as we are waiting for another team to finish using a shared environment”.
- “We cannot run our tests as an integrated component has not yet been developed fully, and we do not have access to it in our environment.”
Given that a tester can spend as much as 44% of their time on test data-related activity [1], the above frustrations are clearly a problem worth solving. Overall, providing data and environments to work in parallel is imperative for achieving the pace and quality aimed for in “Agile” ways of working and CI/CD.
Achieving test autonomy
Test autonomy is key to parallelisation. It can be split into two categories: The independence tests need to run in parallel, and the independence testers need to work side-by-side. Let’s call the latter “tester autonomy”.
Considering first test autonomy, automated tests each require unique data combinations to run in parallel. Otherwise, they might fail when one test uses up another’s data. This challenge is discussed in an excellent video by Sauce Labs’ Titus Fortner, which inspired the language of “test autonomy” used in this article.
The challenge of achieving test autonomy today is that an increasing number of parallelised tests require increasingly-complex data, and these tests will change constantly to support rapid software development. Manually matching unique data combinations to tests is simply too slow and brittle, risking bottlenecks and errors. Instead, an on-the-fly and “just in time” approach is needed.
Automated test data “Find and Makes”
Curiosity’s Enterprise Test Data offers test data “find and makes” that hunt for data from across interrelated data sources. The data “finds” are based on exact test criteria, which are passed automatically as parameters by tests. This can be achieved, for example, by firing an API call to a list of reusable data lookups, with a simple function embedded in automated test scripts.
But what if data cannot be found in available data sources, or if multiple tests require the same combinations? To ensure testing agility, the test data “finds” are integrated with automated data “makes”. These “makes” produce new data when needed, ensuring that every test has the data combination it needs on-the-fly.
A range of techniques can be used to make new data as needed, as shown in the below video. For example, Enterprise Test Data might look for similar data and modify it, automatically parsing a data query to understand the type of data needed. Alternatively, existing data combinations might be cloned and assigned to different tests, with each data clone assigned unique identifiers. Synthetic test data generation might additionally create new data from scratch.
Automated test data “find and makes” ensure that parallelised tests runs on-the-fly, with on demand test data. Resolving data “just in time” ensures that each test has accurately matched data, even as tests change. This in turn resolves the time lost finding, making, or waiting for test data to become available, helping to solve one of the greatest bottlenecks in testing and development.
Test data allocation
Test data allocation further supports test autonomy, and integrates seamlessly into Enterprise Test Data’s “find and makes”.
Allocation matches data combinations to tests within a shared environment. Data within a database, file, API or message can then be locked for use by an individual test, or can be set to have "read" privileges if the test does not need to edit it. Read privileges allow other tests to access the data without editing it.
Allocating data to tests ensures that every test is equipped with the data it needs, without other tests editing or using that data up. At the same time, parallel tests still enjoy all the data they need, by virtue of integrated test data “find and makes”.
Achieving tester autonomy
We’ve now looked at techniques for ensuring that every parallel test in a suite comes equipped with the data it needs on-the-fly. Let’s now look at techniques for ensuring that every tester and developer can access the data they need in parallel.
Database virtualisation and orchestration
One of the greatest barriers to providing parallelised test data lies in the time and expense associated with copying data.
Organisations today still frequently make physical copies of non-production data. Ops teams run through a complex set of manual or semi-automated processes, striving to create copies of data that resemble complex production relationships. This risks massive bottlenecks and runaway costs, as ever-growing data copies increasingly consume physical infrastructure.
Today, data refreshes can take longer than an iteration, meaning that data is always out-of-date by the time it reaches testers and developers. Teams are furthermore often forced to share environments, as physically copying data cannot scale to meet the demands of parallelisation. They then face the frustration of useful data being edited or deleted by another team.
Database virtualisation instead allows organisations to make lightweight, virtual copies of data at a fraction of the time and cost of making physical copies. It provides a cost effective, scalable solution to parallel data access needs, where as many as 30 databases can run on a single 8 core server.
Spinning up virtual databases can also take less than a minute, with full version control over the data. With integrated database orchestration and a self-service test data portal, virtualisation allows parallel teams and frameworks to spin up the exact databases they need, exactly when they need them.
Data cloning
If teams are sharing a database, it’s imperative that they can access data combinations in parallel. Automated data cloning supports tester parallelisation, just as it ensures that automated tests can access equivalent data combinations in parallel.
If two testers require the same data combination, data can be cloned and each clone assigned unique identifiers. Both testers can then access and update data that is functionally equivalent, without impacting one another. This avoids the frustration caused by data cannibalisation, when one tester or team uses up, edits, or deletes otherwise useful data.
Self-serve data and reusability
To support true parallelisation, test data processes like cloning and virtualisation should be reusable on demand. Otherwise, testers and developers will remain dependent on an Ops team to create the data they need, creating a dependency that undermines parallel ways of working. Ideally, every requisite test data process should be reusable on-the-fly, including masking, generation, subsetting, and beyond.
Automating test data utilities and making them parameterisable on demand alleviates test data bottlenecks, as testers and automated tests can trigger the test data jobs they need, exactly when they need them.
With Enterprise Test Data, each configured test data job becomes reusable from a central catalogue. The jobs can then be triggered on-the-fly, passing in parameters “just in time” to create and provision the right data at the right time.

Reusable data masks and generation jobs can be triggered on-the-fly, providing the right data to tests and teams in parallel.
Automated tests can pass parameters into reusable jobs via API calls, while orchestration engines, schedulers and batch processing can likewise trigger jobs. Parallel testers and developers can similarly trigger test data processes on-the-fly. For example, they can fill out configurable forms to self-provision data, selecting from drop-downs and inputs to pass parameters into the reusable test data jobs:
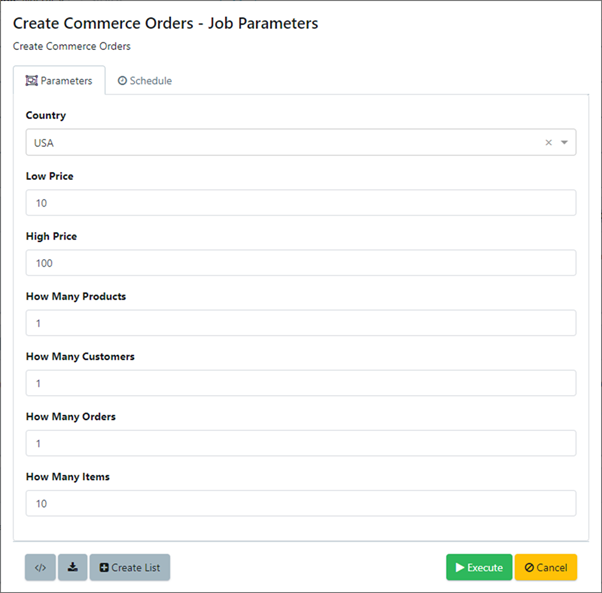
Self-service forms configured in intuitive business language allow testers and developers to request the exact data they need on demand.
If no data can be found, automated data “find and makes” plug the gaps, ensuring that every tester receives the parallel data they need. Each test data request made by testers can additionally feed a central list of reusable test data queries. The lookups can then be triggered by test automation or CI/CD frameworks, or re-used to refresh virtualised environments with a comprehensive test data
Exposing parameterizable and automated jobs to testers and tests ensures that both receive the data they need on-the-fly. Resolving a comprehensive set of test data utilities “just in time” provides complete and compliant data-as-a-service, even as the exact data needed in testing and development changes.
Test data for test autonomy
This article has now discussed a range of techniques for providing data in parallel to both tests and teams. Providing this autonomy to tests and testers is imperative to removing test data blockers in automated testing, while providing the parallelisation needed for iterative delivery and CI/CD. To learn more about how Enterprise Test Data provides data “just in time” to parallel teams and frameworks, check out Curiosity’s Test Data-as-a-Service solution brief.
References:
[1] Capgemini, Sogeti (2020), The Continuous Testing Report 2020. Retrieved from https://www.sogeti.com/explore/reports/continuous-testing-report-2020/ on 08/07/2022.


