



The previous article in this series set out how a successful data migration hinges on a range of criteria:
- Detailed understanding of the legacy system data, in both its contents and structure.
- Clear and complete requirements setting out the new system in full.
- Data for testing every requirement, including outliers, negative scenarios, and test data for new functionality.
- Testing early and regularly enough to perform fixes caused by unexpected data or behaviour.
Unfortunately, this is rarely the case at organisations today. This exacerbates the migration risk factors set out in the part two of this series, and underpins the unacceptably high migration failure rates set out in part one.
Fortunately, a unified solution can mitigate these risks, establishing the upfront understanding, requirements and data needed for a successful migration.
Want to read every article in this series? Download this entire article series in Curiosity's latest eBook, How to avoid costly migration failures.
A unified approach to data migration projects
This unified approach to data migration is made up of three overlapping stages:
- Data analysis and archaeology. Start by ensuring that you understand the legacy system data, running utilities to verify your teams’ assumptions. Understand what data exists, where sensitive data resides, and which relationships must be respected in the new system.
- Validate and refine the new system requirements. Improve the requirements for the new system based on newfound understanding of the legacy system data. Is there robust functionality for processing all data types, both positive and negative? Are the requirements clear, concise and complete with respect to the data, avoiding bugs caused by incomplete or ambiguous user stories?
- Generate complete and compliant test data. Synthetic test data generation can be rooted directly in the completed and clarified requirements. This creates realistic, but fictitious, data for every test, enabling rigorous migration testing and compliance with data privacy regulations.
Let’s now look at particular tools that can support these three overlapping stages in a unified approach to data migration.
Tools for understanding legacy data
Let’s look first at tools for understanding the legacy system data.
Organisations typically rely primarily on subject matter expertise for knowledge regarding legacy system data. However, for poorly documented legacy systems, there’s a fair chance that SMEs will have left the organization, taking knowledge with them. Given the sheer complexity of legacy system data, there’s also the risk that people’s understanding will be inaccurate and incomplete.
Relying on human knowledge alone is simply not enough to mitigate the risk of migration failures caused by poor system understanding.
Human assumptions should instead be verified and validated using technology, feeding this uncovered knowledge into “living documentation” of the system under migration. This averts risk, while “future proofing” development by maintaining understanding for future development:

Automated data analysis verifies and helps complete human understanding regarding legacy data, feeding up-to-date “living documentation” to avoid growing technical debt.
Automated data analysis
During a migration, automated data analysis and modelling help understand what legacy data exists, along with the relationships that must be respected in the migrated system. This includes relationships within and across databases, such as primary and foreign keys.
Automated analysis can additionally perform averages, counts and aggregates, and can measure the skewness of data. It can further identify minimum and maximum values, while “kurtosis” identifies rare values:
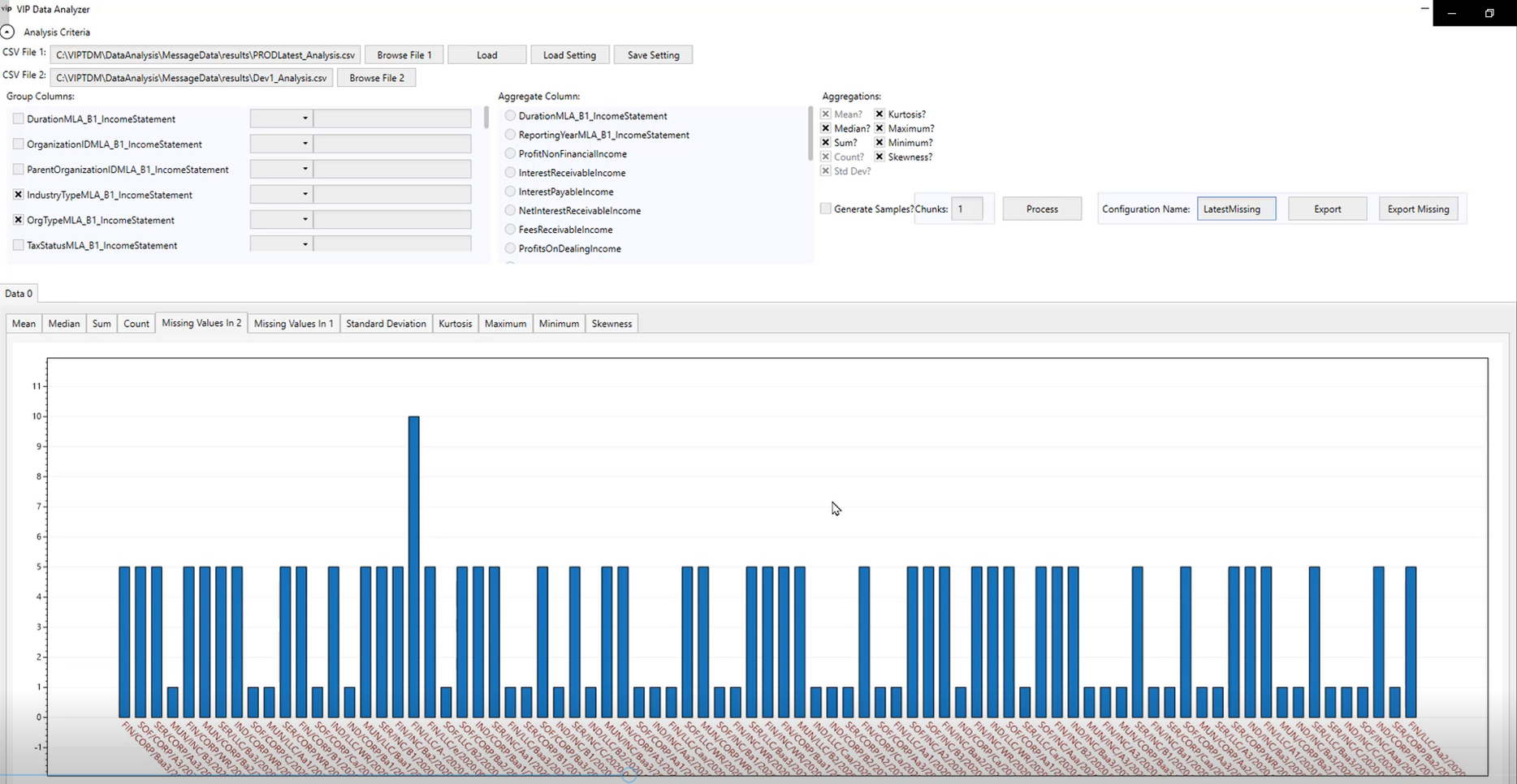
Automated data analysis provides understanding of legacy system data and identifies gaps in test data.
In addition to supporting understanding the legacy system data, this analysis also helps to understand missing data needed for testing.
Data comparisons
Automated data comparisons between environments provide an additional tool for understanding data, which can again be used to identify data needed for rigorous testing. For example, you might compare data density in production and development environments to identify gaps, or might compare data before and after you’ve transacted against it.
Running “fuzzy comparisons” of data in the legacy and migrated system data further provides a quick approach to testing, looking for key differences between data before and after a migration:
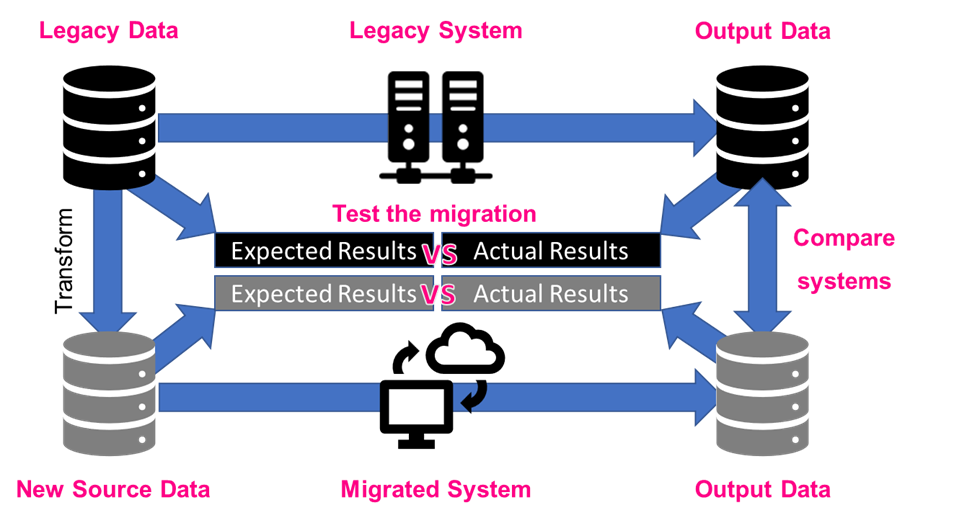
Automated data comparisons aid with understanding of the legacy system data and offer a rapid technique for testing data migraitons.
Data profiling
Data profiling offers specialised analysis that identifies potentially sensitive information. It searches for personally and commercially sensitive information in data, for instance searching column names, using regular expressions, and matching data against seed lists.
Data profiling is valuable for mitigating compliance risks during a migration. It might, for example, inform test data masking and generation. This reduces the spread of sensitive information to less-secure non-production environments, while supporting the principles of data minimisation and purpose limitation.
Requirements refinement and “living documentation”
Understanding of legacy and migrated systems must be stored and updated iteratively. Otherwise, you risk growing technical debt, and quality issues stemming from incomplete or ambiguous system understanding.
Formal modelling offers a requirements gathering technique that lends itself well to complex data structures, while often also being easily maintainable as “living documentation”.
Visual models are well-suited to map out complex data journeys, as they mirror data equivalence classes in a concise system picture. Flowcharts, for instance, map out a system’s cause and effect logic into a series of “if this, then this” statements. This shows complex system structures clearly and concisely, allowing you to document and understand overlapping data journeys at a glance:
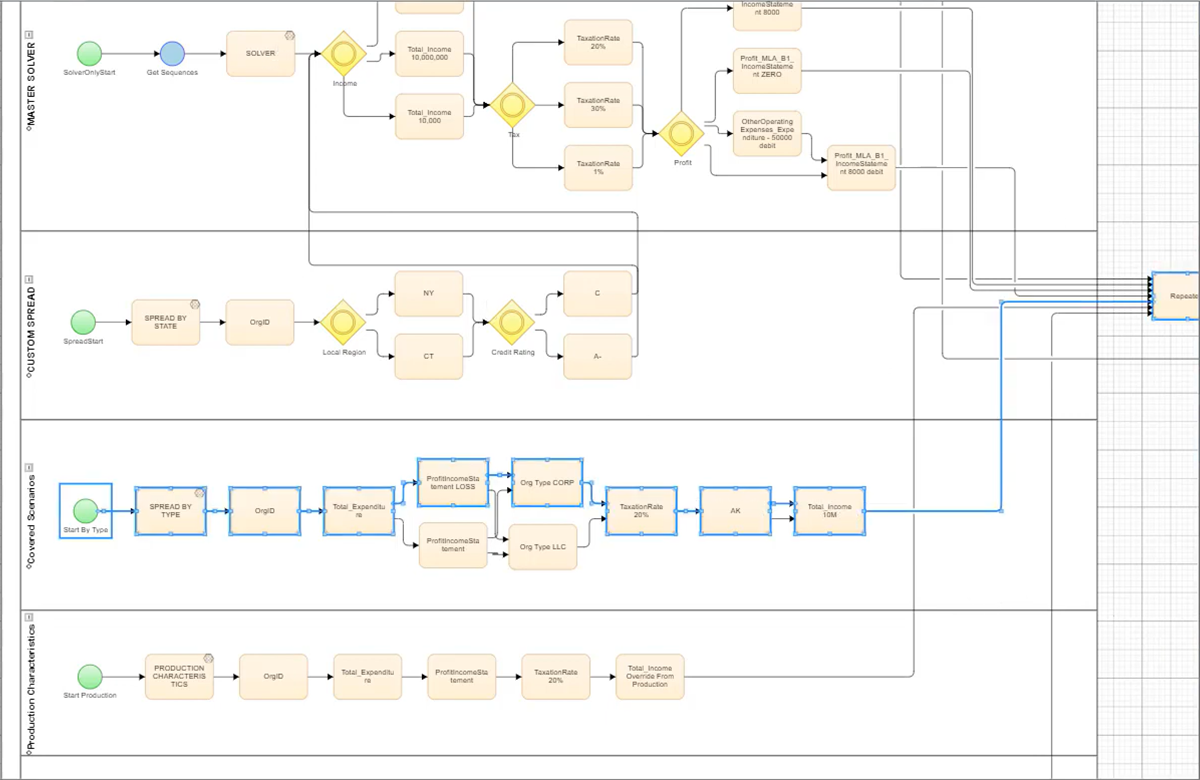
Formal flowcharts map complex data structures clearly and concisely, providing an understanding of the “data journeys” under migration.
Logical modelling is overall a better fit for data-driven systems than inherently-ambiguous, written requirements.
Flowcharts offer the additional benefit of being familiar to many business analysts and product owners, enabling close collaboration between system testers, developers and designers. The formal nature and logical precision of flowcharts further enables automated test and data generation, enabling iterative testing as the models change throughout a migration project.
Test and data generation
As discussed in part three of this series, testing late and with incomplete test data are key causes of data migration failures. Auto-generating test cases, scripts and data from completed requirements models mitigates this risk, iteratively generating complete and compliant data for migration testing.
Flowchart modelling of the data under migration enables the application of automated test and data generation algorithms. The logically-precise flowcharts act as a directed graph, to which automated graph analysis can be applied. These algorithms act like a car GPS, identifying possible routes through a city map:
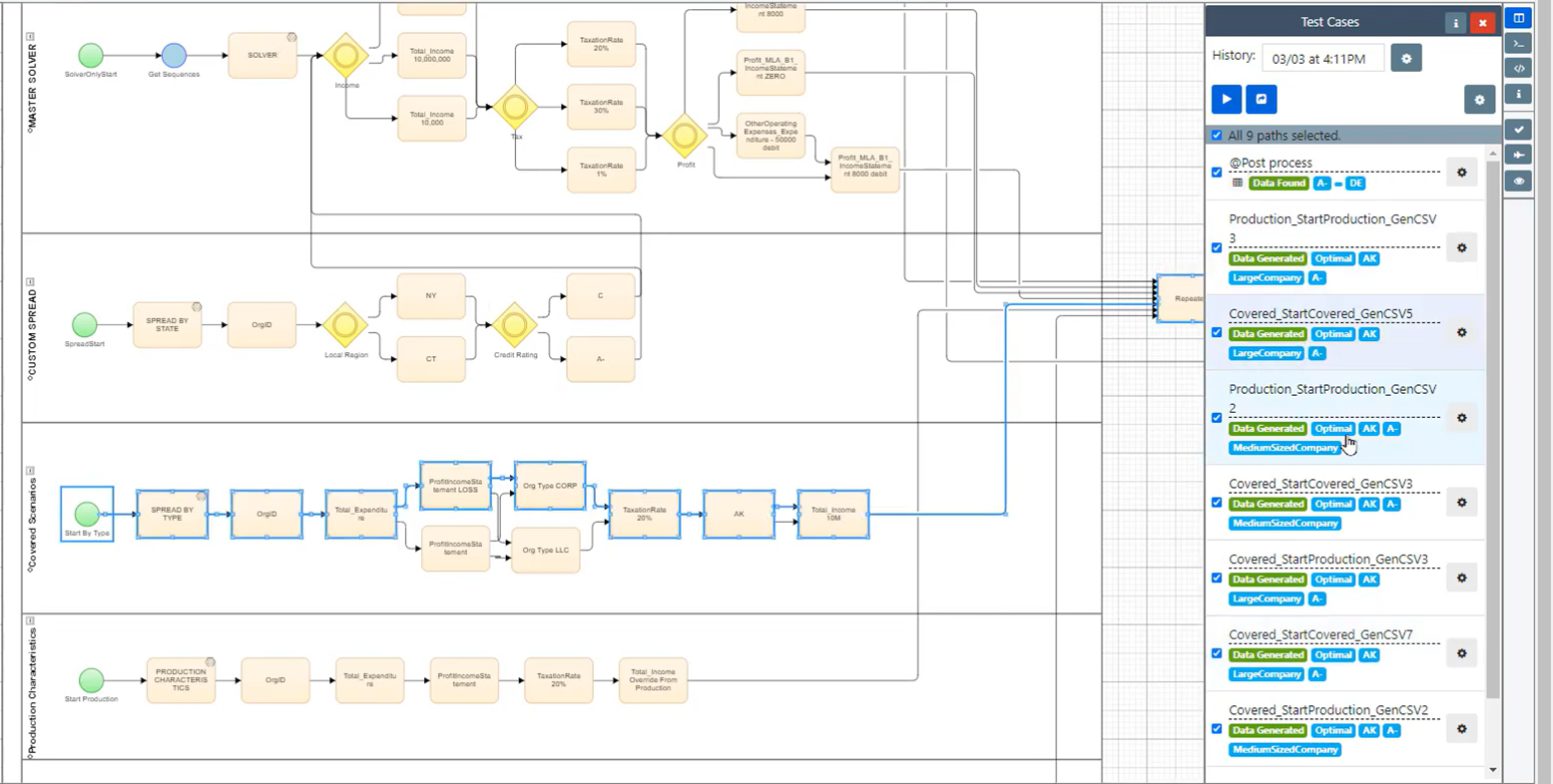
Formal flowchart models enable automated test generation, identifying positive and negative combinations for rigorous data migration testing.
Each path through the modelled data is equivalent to a data journey and a test case. The automated test generation algorithms can generate an “exhaustive” test suite that covers every path through the model. In most cases, however, optimisation algorithms create the smallest set of paths required to cover each distinct logical combination, or to satisfy a given risk profile. This reduces the total test volume, while generating a rigorous set of data for migration testing.
The automated test generation creates the positive and negative data scenarios needed to avoid costly bugs and production outages post-migration. Using Curiosity’s Enterprise Test Data platform, the creation of consistent data journeys can be driven by data generation functions defined at the model level.
Alternatively, the flowcharts can embed reusable Enterprise Test Data jobs. These jobs find, make and mask data as tests are auto-generated, ensuring that every test scenario is fulfilled by complete and compliant test data:
Integrating reusable Enterprise Test Data jobs with automated testgeneration ensures that every migration testcomes equipped with complete and compliant data.
Rigorous testing with this approach can far start earlier during migration projects, because test and data generation is rapid and rooted in the requirements. “Shift left” testing can therefore occur early, replacing the late-stage testing that leaves no time to find and fix quality issues during a migration:

“Shift left” migration testing is rooted directly in requirements and can begin far earlier during a migration project.
Beyond the migration: Rapid development and future-proofing
This unified approach to data migration avoids the 4 common for migration failures, which were identified in part three of this series. To conclude this series, let’s summarise how the proposed solution avoids these common data migration pitfalls:

The value of this approach does not, however, start and end with the migration project. By implementing this approach for a migration project, you are further equipping your teams with the requirements, tests and data needed for future development. This helps “future proof” the migrated system. It provides the tools needed for ongoing innovation, as well as the requirements and data needed to eventually migrate away from the system:
- Clear requirements – The easy-to-maintain flowcharts retain knowledge and provide clear documentation of the new system. This future-proofs development and avoids costly rework, as testers, developers and BAs can refer to the clear requirements for system understanding.
- Optimised regression tests – Updating the central flowcharts generates in-sprint tests and compliant data as the new system changes. This enables rapid development post-migration, enabling ongoing innovation without the risk of costly bug
- Data available in parallel – Often, delivery teams today are constrained as they wait for a migration or development to finish. In this approach, you can generate the data these teams need to develop integrated components. This boosts agility, removing a key bottleneck and blocker to parallel ways of working.
The unified approach set out in this article series accordingly aims to ensure a successful migration, while developing the tools needed for ongoing development post-migration. To learn more about these techniques for migration success and rapid development, book a meeting with a Curiosity expert today.


