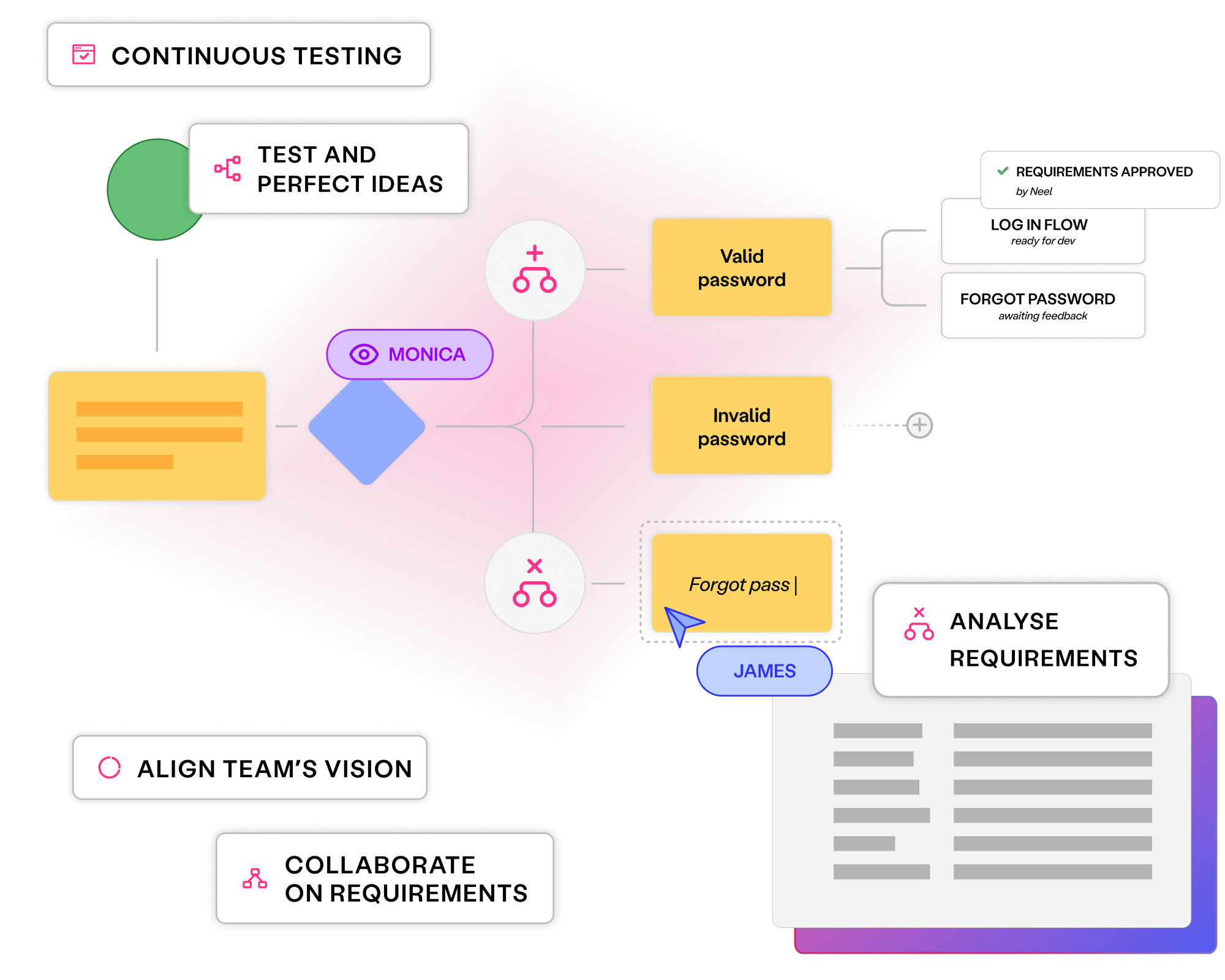
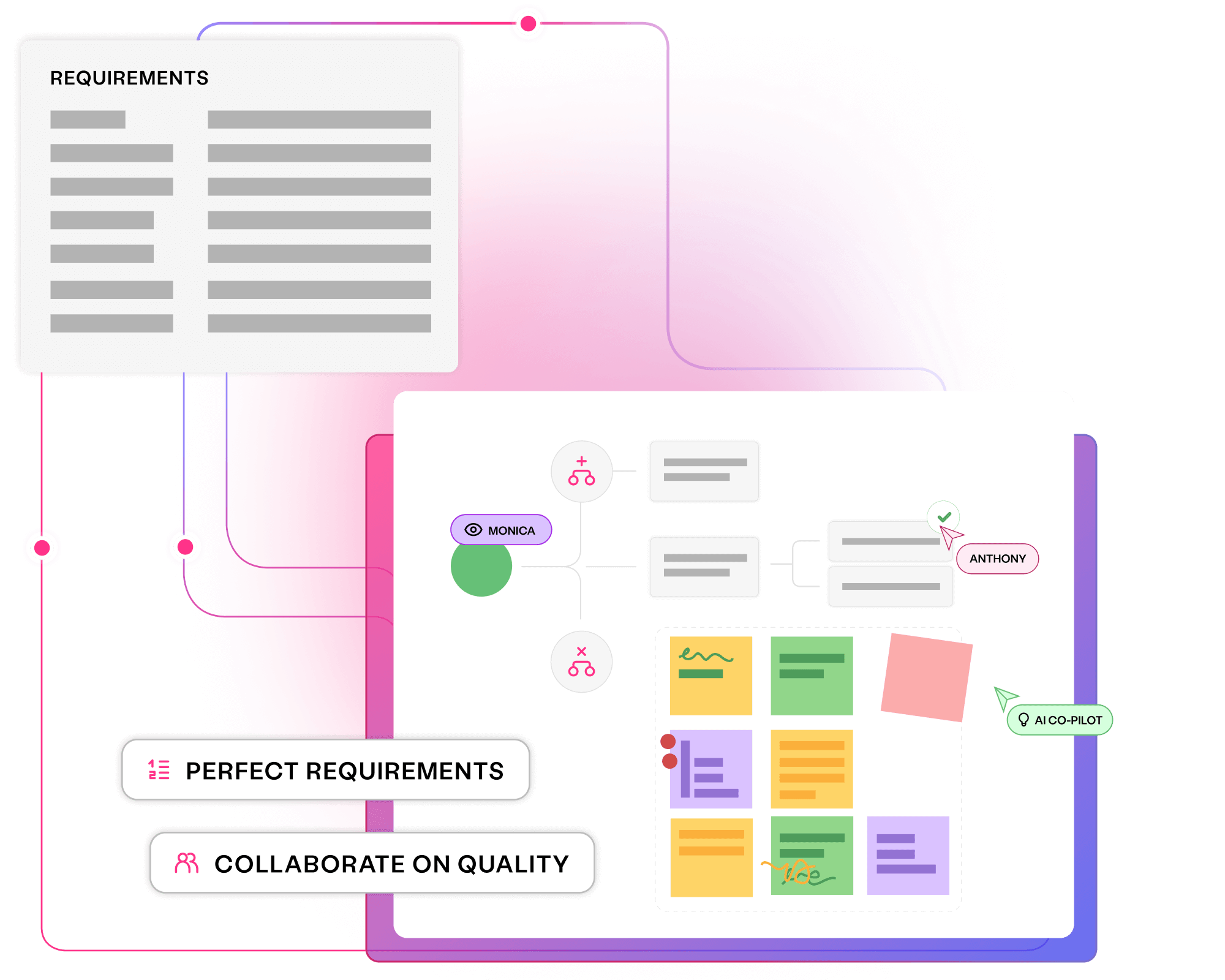
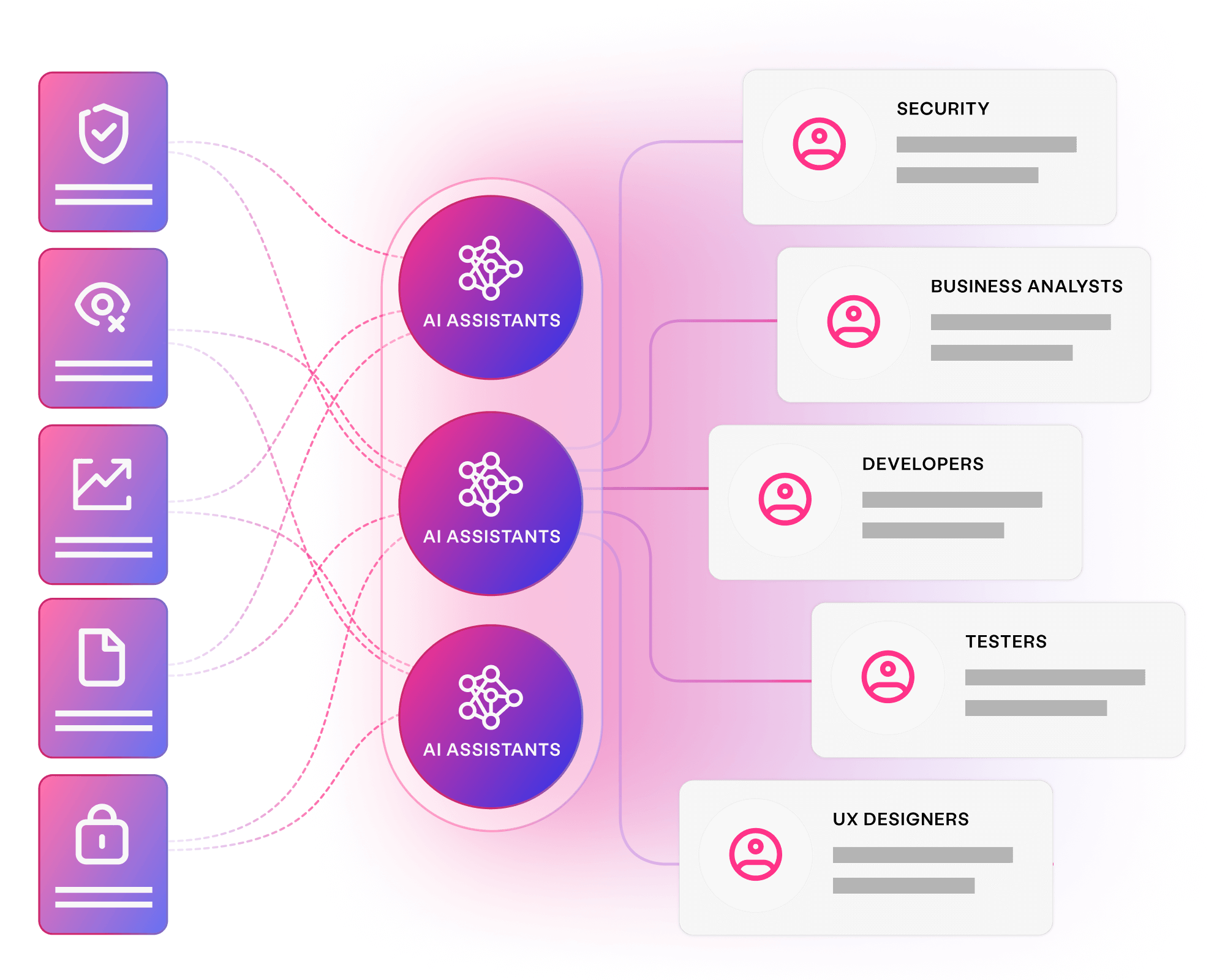
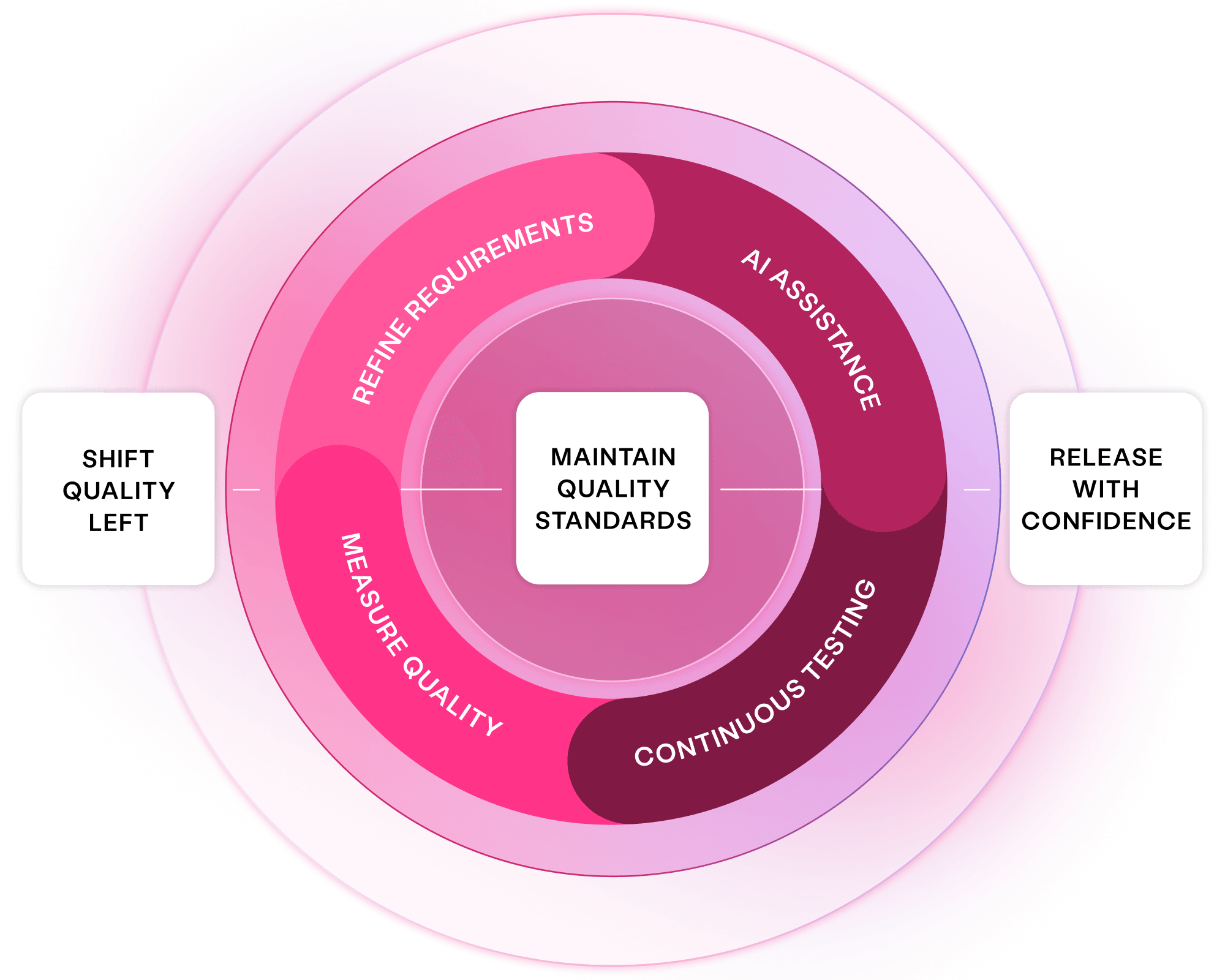
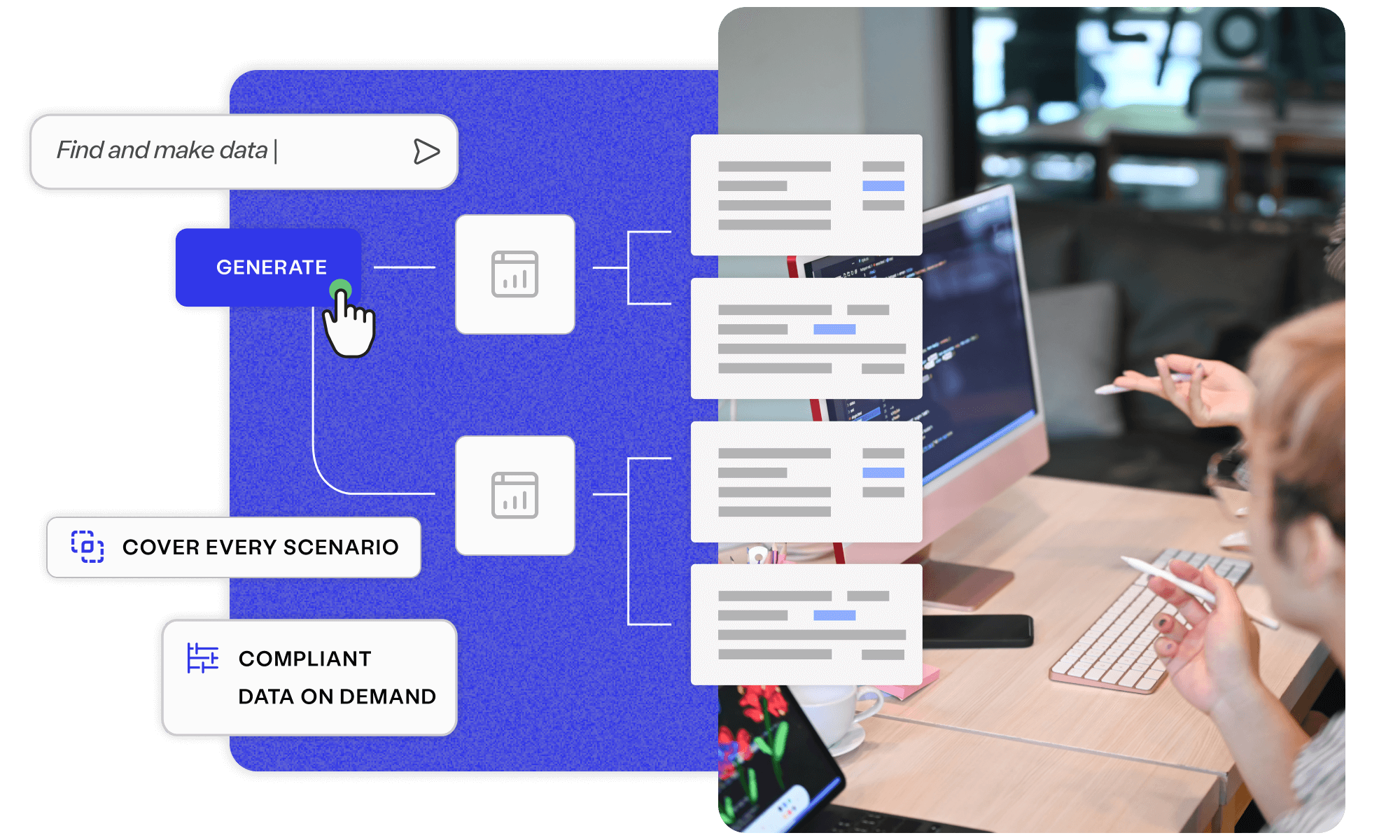
Align all stakeholders to quality outcomes and create critical assets early, delivering superior software at speed with Curiosity's platform.
-
Collaborate seamlessly on organisation-wide quality goals
-
Generate key assets upfront, with measurable coverage to prevent bugs
-
Maximise productivity, with minimal toil and rework