



At Curiosity, we talk about test data extensively, because we believe test data is repeatedly neglected in testing and development discussions. Outdated test data management practices are today the cause of release delays, costly bugs and compliance faults; yet, the detrimental impact of these TDM practices is not always reflected in the agendas of CTOs.
While CTOs focus on improving testing and development, the software delivery industry overall often neglects the challenges that come with poor, outdated test data management practices. In fact, testers at around half of organisations report that they don’t have sufficient data for all their testing, and half report that they are unable to manage the size and complexity of their test data sets [1]. And yet, parallel and automated development pipelines are fuelled by data - without it, no testing or development is possible.
Unless test data is paid its due attention, the challenges associated with TDM will persist. This article will highlight five test data challenges that every CTO should know about, and techniques to help you overcome them.
This blog is part 1/4 in a series focusing on test data modernization. Check out the next three parts below:
- 5 Techniques for Overcoming Test Data Bottlenecks.
- 5 Solutions to Test Data Coverage Issues.
- 5 Ways to Keep Your Test Data Compliant.
1. Low-variety test data
Achieving sufficient test coverage in-sprint reduces the risk of finding costly bugs after testing and release, reducing defect remediation costs and the negative impact of defects on end users. High test coverage requires high variety data. This rich test data is needed to mitigate the risk of unexpected behaviour, covering outliers, edge cases, and negative scenarios when executing tests.
However, organisations still commonly use low-variety copies of production test data, either masked or in its raw form. This repetitive data satisfies only a fraction of the tests needed to de-risk rapid releases, leading to low test coverage and faulty releases.
Testers today frequently lack both the amount and variety of data they need to meaningfully test systems. In fact, only 39% believe that their testing covers everything that’s needed [1].
The test-Driven allocation of synthetically-augmented data helps alleviate this problem by assigning exact data combinations to tests and automation frameworks on-the-fly. The rich synthetic data contains combinations not commonly found in production data sources, including the outliers, unexpected results and negative data needed for rigorous in-sprint testing.
The use of synthetic test data should be high on the list of priorities for CTOs today, as it not only supports test coverage, but also helps alleviate many of the other challenges covered below.
2. Manual data creation and maintenance
While undermining quality, manual test data practices further create bottlenecks in DevOps and CI/CD Pipelines, as testers waste time finding, making, or waiting for test data. This manual input in otherwise automated pipelines is simply too slow, as applications and test scenarios evolve constantly, and test environments continuously require diverse and updated data.
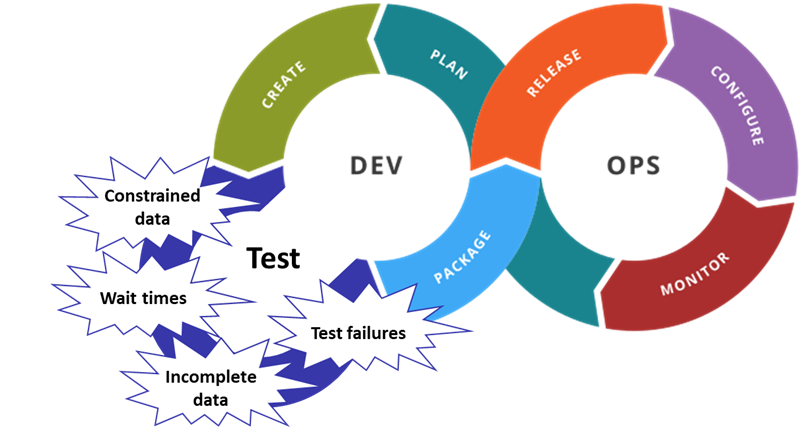
Any manual intervention to find, make or “fix” test data is too slow for a world of DevOps and CI/CD. Original Image: Khanargy, Wikimedia Commons, published under CC BY-SA 4.0 license.
Outdated TDM practices create a situation where test data is always one step behind both automated testing and the systems under test. This undermines test coverage and testing agility, while tests fail due to a mismatch between out-of-date test data and the latest system.
Test data maintenance is arguably one of the greatest test data challenges. This is reflected in the 2021-22 World Quality Report, which found that 49% of teams are unable to manage the size and complexity of their test data sets [1]. Curiosity’s own experience suggests that the scale of the problem might be greater than this, while the growing complexity and pace of development is only going to increase the challenges created by slow and manual test data maintenance.
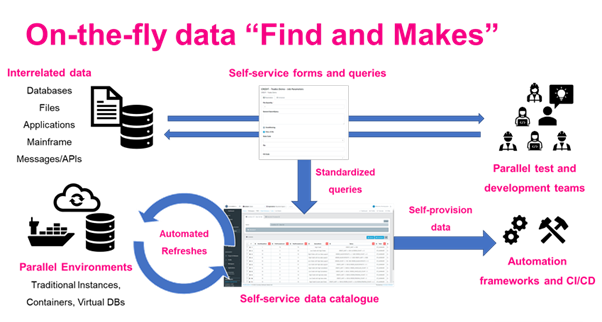
Moving away from slow and manual test data processes is key to keeping up with DevOps and CI/CD pipelines. CTOs should consider automated test data solutions, moving from Test Data “Management” to Test Data “Automation”. This includes automated “Find and Makes”, which search rapidly for the data combinations needed in testing and development, applying AI-based techniques to generate the missing data needed for testing on-the-fly.
3. Test data provisioning across teams and frameworks
Test data provisioning challenges are directly related to manual data creation and maintenance, and further add to delays created by test data. Data provisioning teams today are frequently stuck with outdated, slow and manual test data processes, conflicting with and undermining the rapid and repeatable automation used in testing and development.
Test data provisioning at many organisations can take weeks or months, and test teams report that a massive 44% of their time is spent waiting for, finding, or making test data [2]. Manually copying test data or refreshing environments simply cannot provide the variety or volumes of data required for parallelised testing and development, and test data is in turn frequently unavailable, incomplete, and out-of-date.
CTOs should consider moving away from slow and manual test data practices. This applies to provisioning data to testing and development, as well the time spent finding and making it once it’s there. In fact, enhancing test data generation and provisioning solutions for teams is seen as essential when working towards making testing more efficient by 56% of organisations [1].
Finding and making data automatically and on-the-fly resolves the time spent by testers looking for and generating data. Today, this can be integrated with automated database orchestration and virtualisation, spinning up affordable virtual data copies in parallel and in seconds.
This rapid and affordable database orchestration resolves data provisioning bottlenecks. It provides parallel teams and frameworks with all the environments and data they need, while the integrated “find and makes” provide the techniques they need to access test data on-the-fly.
4. The increasing complexity of systems and data
The increasing complexity and magnitude of systems and environments risks adding to the bottlenecks and quality issues created by manual TDM techniques. In time, inertia with regards to test data “best practices” risks exposing systems to even more damaging bugs and delays, as supposedly parallel teams wait even longer for data sets that can satisfy only a fraction of the tests needed in-sprint.
Hybrid enterprise architectures are today growing increasingly complex. As new technologies are adopted, old technologies do not go away, and systems become a complex patchwork of the legacy and modern.
Each modernisation project or cloud migration today can introduce new technologies that must integrate with business-critical mainframe and legacy systems. Testing in turn requires an increasingly complex set of integrated data for end-to-end testing, mirroring the increasingly complex systems under test.
The growing complexity of this interrelated test data risks adding to test data bottlenecks, while often adding to the likelihood that tests will fail due to misaligned data sets.
If testers and developers are left to find and make test data manually, they will need to hunt across even more complex sources, while seeking to keep the intricately related data aligned. When relying on a central team, bottlenecks will likely mount if this team is equipped with manual processes and scripts for provisioning data from many different sources.
On demand test data containerisation and virtualisation offers a solution to growing data complexity, rapidly provisioning data that mirrors complex hybrid architectures.
With automated and on demand database containerisation, data provisioning can mirror fast-changing systems, as testers and developers rip-and-replace integrated data sets in containerised environments. Data versioning further allows parallel teams to spin up the requisite combinations of versioned data, testing rigorously against fast-evolving hybrid architectures.
When integrated with test data utilities like data generation, masking, and subsetting, the on demand containerisation provides a solution for creating rich, compliant, and integrated data sets, pushed automatically to on demand test environments.
5. Increased data protection and security legislation
All of the challenges above can be credited for delays and buggy releases. A different, but equally or potentially more costly risk comes in neglecting data protection legislation.
Failing to comply with data protection legislation can be a potentially devastating oversight, as fines under EU GDPR can exceed €20 million. However, data compliance requirements extends beyond the EU, with legislation including Canada’s CCPA, India’s PDPB, The California Consumer Act and Brazil’s LGPD.
These laws have increased the complexity of managing test data, while often adding to the risks associated with using raw production data. Yet, testers at 45% of organisation admit that they do not always comply with security and privacy regulations for test data [1]. For the many organisations who still use raw production data in less secure test and development environments, this risks legislative fines, customer churn, and reputational damage.
Legal and compliance leaders should build a culture of responsible data use to prevent data breaches and remain compliant. Synthetically augmenting data as you mask it supports such a culture in testing and development. Effective data masking identifies sensitive information across databases and files, anonymising it before the data is moved to non-production environments. Integrating data generation furthermore produces the data needed for rigorous, continuous testing, turning compliance requirements into an opportunity for more rigorous testing.
Seamless, secure, smarter test data
The challenges created by outdated test data management can pose a risk to all stages of the software delivery lifecycle, while also often risking an organisation’s legislative compliance.
CTOs today should consider moving from test data “management” to automated solutions, capable of fulfilling rapid and evolving data requests securely and on-the-fly.
This blog is part 1/4 in a series focusing on test data modernization. Check out the next three parts below:
- 5 Techniques for Overcoming Test Data Bottlenecks.
- 5 Solutions to Test Data Coverage Issues.
- 5 Ways to Keep Your Test Data Compliant.
Footnotes:
[1] Capgemini, Sogeti (2021), World Quality Report 2021-22. Retrieved from https://www.capgemini.com/gb-en/research/world-quality-report-wqr-2021-22/
[2] Capgemini, Sogeti (2020), The Continuous Testing Report 2020. Retrieved from https://www.sogeti.com/explore/reports/continuous-testing-report-2020/





{kind=link}