


Data Subsetting in 2 Minutes
Reduce the size of non-production data sets while retaining data variations and relationships needed for rigorous testing. Test Data Automation extracts referentially-intact, coverage-complete subsets on demand, shortening testing cycles, minimising storage costs, and finding bugs at less cost to fix.

Manual test data provisioning is slow, costly, and misses bugs
Too much testing and development time is today wasted waiting for oversized data sets, or hunting for combinations in repetitive data. Manually copying data and writing SQL is slow, complex, and breaks data relationships. It cannot provision data quickly enough for parallel teams, who compete for out-of-date data copies. Tests then fail due to inconsistent data, or when data is edited in a shared environment. Running the repetitive data is likewise slow and produces cumbersome results, yet misses bugs due to missing data combinations. Storing and running bloated data further incurs runaway infrastructure costs, and can risk non-compliance with data minimisation requirements. A rapid, parallelised and “rightsized” approach is needed to data provisioning.

On demand subsetting: Shorter release cycles with rigorous testing
Data subsetting from Test Data Automation provides the right volumes of test data on demand, shortening release cycles, minimising infrastructure costs, and supporting data minimisation requirements. The on demand subsets extract just enough data needed to fulfil relationships and create referentially intact data sets, “crawling” iteratively across databases to gather inter-related data. Testers, developers and automation frameworks can self-service the smallest set of data needed for rigorous testing, leveraging three flexible subsetting methods. Scenario subsets provide on demand data for particular test cases. Criteria subsets fulfil user-defined criteria. And “covered” subsets create the smallest data set needed to retain the variations found in source data sets.
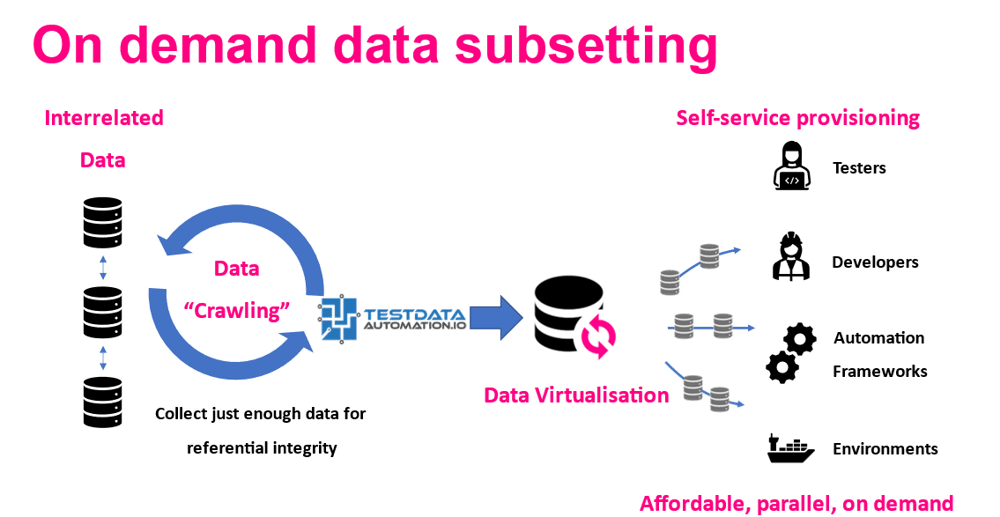
Each subsetting job is reusable on demand from Test Data Automation’s central portal, shortening data provisioning time and reducing the strain placed on over-worked DBAs. The subsets can additionally be virtualised and provisioned rapidly to parallel teams and environments, minimising nonproduction infrastructure costs and data provisioning bottlenecks. Further time is saved during testing, as the concise data sets require less time and fewer resources to run, while testing with the smallest possible data set supports legislative compliance. With self-service subsetting from Test Data Automation, you can provide on demand data for parallel teams and technologies, accelerating the delivery of quality software while minimising non-production infrastructure spend.

Parallel test environments, minimal infrastructure costs
Watch the two-minute overview of Data Subsetting from Test Data Automation, to see how:
-
Test Data Automation provides granular methods for reducing the size of data sets, while retaining the relationships and variations needed for testing and development.
-
The concise subsetting avoids runaway non-production storage costs, crawling iteratively across data to collect just enough interrelated data to create referentially intact data sets.
-
Three types of subsets reduce the size of data without reducing variety, collecting data to fulfil individual scenarios, to fulfil specified criteria, or to shrink data while retaining its variations.
-
A self-service portal avoids data provisioning bottlenecks, enabling testers, developers and automation frameworks to self-provision the subsets they need in parallel and on demand.
-
Integrating subsetting with database virtualisation provides data sets at a fraction of the cost of making physical copies, creating virtual copies in seconds for parallel teams and technologies.
-
Testing with concise subsets reduces run times and produces less-cumbersome run results to analyse, further shortening release cycles and optimising the use of non-production resources.
-
Testing and developing with the smallest possible data set can support legislative compliance requirements around data minimisation, reducing the risk of devastating fines.

Speak with an expert
Discover the data you need for faster software delivery.