


Find and Reserve Test Data
Don’t waste release cycles finding, making and waiting for test data. Test Data Automation provides data on demand to parallel testers, developers, and automation frameworks. Self-serving complete and compliant data accelerates software delivery, boosts quality, and cuts provisioning costs.

Test data: The biggest bottleneck in your software delivery?
How much quicker could your release cycles be without manual data provisioning? Test and development teams can spend 20+% of their time today waiting for, finding, and making data. They hunt laboriously through large and repetitive data sets, while provisioning teams can never copy enough data for parallel teams and frameworks. Engineering instead waits idly for shared data to free up, while tests fail due to broken relationships in manually copied data, or when another test edits shared data. The unwieldy data further contain just a fraction of the combinations needed for rigorous test coverage, and is always growing out-of-date relative to new functionality. Testing and development misses costly bugs, while delays, compliance risks, and provisioning costs mount.

On demand data for every team, technology and scenario
Test Data Automation provides self-service data for developers, testers and CI/CD tools, who can deliver quality software faster and at less cost. “Just in time” data finds hunt automatically across integrated data sources, provisioning data sets that reflect complex relationships. Synthetic data generation integrates with the finds to maintain test coverage and quality, making missing combinations on-the-fly for rigorous testing. The complete and consistent data is further available in parallel and without constraints, cloning combinations and generating new ones when parallel teams and tests need the same data. Finding and making data “just in time” additionally keeps test data up-to-date relative to the latest system and requirements, testing early and without failures.
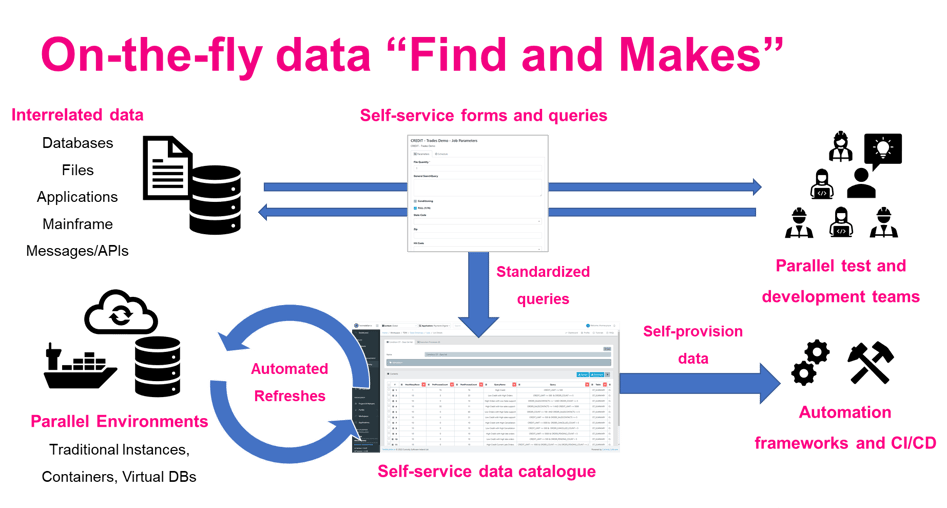
Testers and developers can self-provision data using intuitive forms, configured using business language, dropdowns, input fields, checkboxes and more. Automation frameworks, CI/CD pipelines, schedulers and environment managers can likewise ping Test Data Automation to self-provision data, rigorously testing at every stage of your DevOps pipeline. Submitted queries can further be stored in a reusable list. Running the list refreshes environments with rich data, while engineers and tests can trigger individual lookups. Data engineers no longer waste time fulfilling repetitive requests. Instead, accurate data is available instantly to parallel teams and tools, shortening release times, reducing provisioning costs, and delivering better tested, better quality software.

Self-service test data unlocks release speed and quality
Watch the two-minute overview of Data Find and Reserve from Test Data Automation, to see how:
-
Test Data Automation automatically hunts across interrelated data sources to find consistent data sets, providing on demand data to shorten release cycles.
-
The automated “Find and Makes” ensure that every test and engineer has accurate data on demand, reserving data in shared environments and generating missing combinations on-the-fly.
-
Testers and developers can use self-service forms to provision the data they need, while automation frameworks, CI/CD pipelines and schedulers can self-provision data “just in time”.
-
Test Data Automation makes data available in parallel and without constraints, cloning data and creating new combinations when multiple tests or engineers require the same scenario.
-
Each data lookup is reusable on demand from a central portal, saving data engineers the toil of fulfilling repetitive data requests and minimising I&O spend.
-
Data Find and Reserves are quick and easy to set up.
Speak with an expert
Shorten your release cycles and deliver better tested, better quality software.